This article originally appeared on the Snowflake blog.
During a cloud migration to Snowflake’s Data Cloud, businesses often struggle to know what data they have on premises, what they should migrate, and in what order. And because of this, many organizations fall into a “lift and shift” approach, where everything is simply copied over—as it messily stands—to the cloud.
This is a less-than-desirable outcome, as your organization is simply moving technical debt from one place to another, kicking the can down the road until it becomes someone else’s problem. Or worse, until minor technical annoyances become major problems, and their fixes steal development time that could be spent improving performance or designing new features that could ultimately increase revenue and decrease costs.
A Data Cloud migration is like moving to a new house
When you move into a new home or condo, you don’t grab the dusty boxes in your garage and dump them in the corner of your new place without knowing what goes where. Instead, you take stock of what items you currently have, decide where they belong, or whether they’re worth moving at all. (Maybe it’s time for a garage sale?)
Just as you wouldn’t fill your shiny, new home with clutter you no longer use, you shouldn’t migrate data that’s outdated or not delivering business value to the cloud.
A data catalog empowers you to inventory your on-premises data and see what you’re working with. You can make sense out of everything in your legacy, on-premises systems and set your organization up for post-migration success.
If you adopt a cloud-native data catalog during your migration to Snowflake’s Data Cloud, you’re better able to accelerate, govern, and optimize your migration, improving the process from a basic “lift and shift” into a “lift, upgrade, and shift”—an opportunity to catalog, organize, prioritize, and optimize your data.
A successful post-migration world means that Snowflake’s Data Cloud will consist of data that provides business value. The migration plan defined through the data catalog provides the reason why the data should be in the cloud. Furthermore, by prioritizing you can migrate data in an iterative manner, thus enabling data teams to start using data quickly instead of waiting for a long “boil the ocean” migration process. Finally, you are guaranteeing that the expenses are justified.
Not all data catalogs are created equal
For your migration to deliver a true upgrade, you need an enterprise data catalog with certain key capabilities.
A fully complete data catalog is essential to a successful migration, and to catalog all your legacy data, you need an enterprise data catalog with a collector that can be pushed onto on-premises systems and send what it finds back to the cloud. On-premises collectors are paramount because more often than not, the data you want to migrate comes from legacy non-modern, non-cloud, on-premises data sources. Without on-premises collectors, you will be missing out on all the on-premises data that needs to be migrated.
You also need a data catalog built on a knowledge graph, which enables you to catalog and understand whatever type of data you discover during your migration, and that shows you how it relates to your other data. A knowledge graph-based data catalog provides your data model with limitless extensibility, allowing it to grow to include resources and relationships from proprietary and legacy systems, which may have not been defined before your migration, without costly and time-consuming infrastructure changes. Without this capability, you may not understand the legacy landscape of your organization, potentially leading to uninformed decisions on what needs to be migrated.
Many of data.world and Snowflake’s shared customers collect, catalog, and understand infinite amounts of disparate data by embracing this powerful functionality.
A data catalog keeps your cloud migration agile
Once your on-premises data is cataloged, you can figure out what data is most important, what data is of the highest business value, and what data sees the most use. And from there, you can create a prioritized backlog of resources to migrate, then iterate through the backlog in an agile manner.
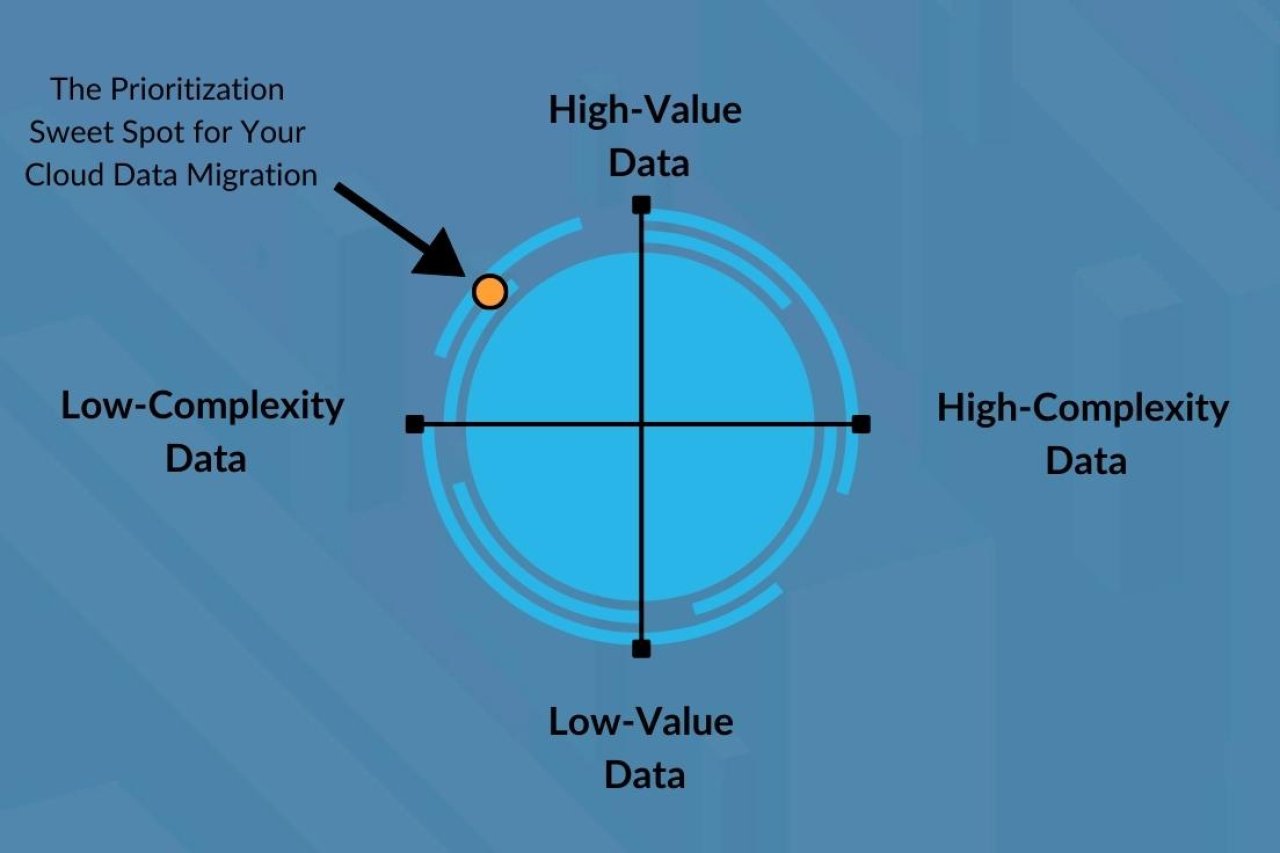
You should prioritize your data using a two-by-two matrix. The axes are high value, low value, high complexity, and low complexity.
Start by identifying high-value data. How to do this? Focus on the importance of business use cases; what are the most visible pain points? Which business users are complaining most about slow data delivery or critical broken dashboards?
Next, identify low-complexity data so you can focus on low-complexity, high-value data to start, moving on to more complex data after you’ve shown quick success and value to your team. By demonstrating momentum, your business leaders will feel more secure in your organization’s investment in a data catalog, and be more inclined to support future data governance initiatives.
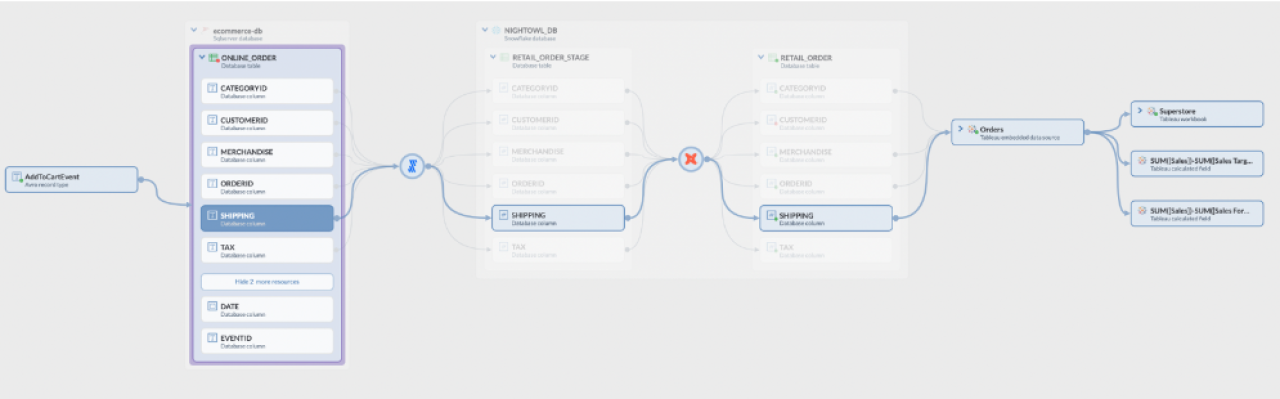
Using the broken dashboard as an example, your enterprise data catalog’s automated lineage viewer—powered by a knowledge graph—lets you understand which data sources inform it; these are the data you should be prioritizing for unraveling, cleaning, and migrating. With any luck, the node in your knowledge graph that represents the dashboard is receiving data from a few, easily viewed and understood data sources, represented by edges. If so, you can consider this “low complexity” data.
If, on the other hand, the node is receiving data from more sources than you want to count, and the edges flowing into it look like a plate of spaghetti, this is “high complexity,” and it should be prioritized after your high-value, low-complexity data.
Your knowledge-graph-powered data catalog gives you insight into this lineage, not just visually but also through graph querying and analysis. For example, automatically inferring node centrality in the graph represents bottlenecks in the lineage (imagine a view that joins many tables and is consumed by many other resources).
Analyzing the metadata knowledge graph gives you an opportunity to reorganize and unravel complex flows and make them easier to maintain. This is your chance to sort it all out, eliminate the spaghetti mess, and build a clear, strong link from data sources to a business-critical resource.
After establishing a plan and starting to execute on the migration of high-value data, it’s time to decide what to do with the low-value data. Perhaps this data doesn’t need to be migrated at all, thus avoiding unnecessary expenses and effort.
Your Data Cloud migration is an opportunity to catalog and make sense of your data
After defining a prioritized backlog of the data resources to be migrated to the cloud and executing on the migration, you are in the position to provide high-value data to your organization. If you come to your Data Cloud migration with a cloud-native, knowledge-graph-based enterprise data catalog, you’ll be equipped and ready to do so much more than simply “lift and shift” your legacy data onto the Snowflake Data Cloud. With the right catalog, you can take stock of, understand, and prioritize your data; view and untangle your lineage; and set your organization up for successful data governance going forward.