Part One
You’ve seen the headlines that closed out 2022 and began 2023: layoffs at Amazon, Microsoft, Meta, Salesforce, and others. You’ve watched the year end as crypto exchanges such as FTX have plummeted and burned, its founder in handcuffs; a modern version of mythology’s Icarus, the crypto bro’s wax wings melting as he flies too close to the Sun.
No doubt you’re pondering the ongoing chaos at Twitter as it enters 2023 shedding employees by the thousands and advertising income by the billions. The NASDAQ is down by 41% over the past year as I write this, and inflation is up, along with the elixir of the Federal Reserve’s fund rate, now boosted for the seventh time since March.
A grim year ahead? That’s the common story. But hold on. While vivid, it’s incomplete. In fact, now is the moment when digital transformation will accelerate the power of data science and analytics. This challenging economy demands it, as I wrote in the International Business Times a few weeks ago.
“There's a ton of really great tech talent that's been tied up in activities that may not be creating that much value,” Erik Brynjolfsson, the physicist who directs Stanford University’s Digital Economy Lab, told an interviewer in early December. Far from a crisis, Brynjolfsson sees technology’s liberation in the otherwise somber headlines: “The real need is to have tech folks go and transform the rest of America, manufacturing, retailing, finance, health care most of all.”
In fact, we already are. What’s shaping up outside the common field of vision is what I’ve called the “Fourth Surge” in the past half century’s data-driven transformation of the economy and society. Sure, there’s a slowdown in Big Tech. But the piece of the digital economy iceberg we see above the waterline should not mask the huge mass below that’s been waiting for an appropriate infusion of talent in order to surface.
The point I want to make here is that while the inexorable growth of data can be measured year-by-year – from two zettabytes in 2010 to nearly 100 zettabytes this year for example – the means by which we harvest and transform this bounty into the capital of our new economy is intermittent, and comes in surges. In the coming days, I’ll post more on the engine of the Fourth Surge, the “Double Helix of Data’s” transformative power that rests on the concepts of Data Discovery and Agile Data Governance. But before that, I want to review the three transformative leaps since the 1970s – as we get ready for the fourth.
As context, readers of my work are familiar with my view of the emerging yet vast ecosystem of a data-driven civilization as a kind of “superorganism”, mimicking the evolution and order of biological systems. In a series in which I wrote about this in detail a little over a year ago, I explained that while our human cognition evolved over millions of years, the evolution of this digital intelligence is occurring on a much shorter timescale. What is emerging are the technological nervous systems and brains of data’s superorganism, what we at data.world call the “data catalog” and the “knowledge graph”. I won’t dwell on that except to say that these powerful graphs drive Google, Meta, Amazon, and other other tech titans. Facebook’s knowledge graph, for example, is the data structure that connects its social graph (the lattice of your friends, likes, tags, etc.) to the architecture generating, managing, optimizing, and monetizing four petabytes of data every day – the equivalent of 2-trillion printed pages of text. Through this channeling of data, Facebook produced the most powerful advertising target engine in history.
Now diminished by Apple’s kneecapping of the social advertising targeting engine in 2020 when it gave iPhone users the ability to tell app-makers not to follow them around the internet – and further eroded by a European Union ruling last week that found the practice illegal – Facebook parent Meta still made more than $100 billion in 2022 from advertising enabled by its social graph.
We at data.world, in turn, are bringing these toolsets to Brynjolfsson’s “rest of America” (and world) – the Fourth Surge, which will be unlike anything you’ve seen yet.
To be clear, my optimism is not to suggest that we ignore real problems in the tech sector and economy at large. I’m certainly not gloating, nor callous toward the nearly 150,000 tech workers who’ve lost their jobs – though a survey in late December found that nearly 80% quickly landed new employment. As noted by Julia Pollack, chief economist at ZipRecruiter which conducted the survey: "They're still the most sought-after workers with the most in-demand skills."
I’ve been an entrepreneur for a long time and, while optimistic, I’m not sanguine. I believe the tech layoffs are just beginning and will reverberate in ways we have yet to see. The temblors shaking the tech titans resonate profoundly in my hometown of Austin where I live and where data.world is headquartered. Meta, as just one example, is backing out of a deal to occupy some 600,000 square feet of a central skyscraper just as our downtown live music and arts scene is struggling back to post-pandemic life.
Nor do I by any means diminish the broader circumstance of an economy buffeted by inflation and what this means for working families. We can’t forget how it’s all been worsened by a ghastly war in Ukraine, and a stubborn COVID-19 virus that is not yet done with us. I had COVID for the second time over Thanksgiving – quarantining during one of my favorite holidays. China’s complex COVID politics and explosion of cases is a parallel concern. Also globally, developing nations are facing a perfect storm of debt and defaults as nearly 200 million people teeter toward famine amid shortages and skyrocketing food prices, an increase of 40 million desperate humans since 2020. Conscience demands our attention to these challenges along with those we must pay to our businesses.
In both instances, this is all the more reason that we need to focus on the technology that’s not in the headlines. This critically includes the neglected backstory of tech hiring at record levels despite the focus on high-profile layoffs. So far this year, the economy has produced more than 200,000 new tech jobs, many in “non-tech” sectors such as manufacturing, according to research by CompTIA, the non-profit association for the technology industry.
“A year ago, an aspiring, young, software engineer would probably be more inclined to join a crypto exchange than the e-commerce division of a bricks-and-mortar retailer,” wrote business professors Vijay Govindarajan and Anup Srivastava in November’s Harvard Business Review. “Now, with technology companies reducing staff, a bricks-and-mortar retailer, or any company with sound fundamentals that has yet to completely modernize, can now outcompete tech companies in hiring the talent it needs.”
We see this vividly at our company, where we are fast expanding partnerships with enterprise customers outside of the tech space. Our new partners include local and state governments, publishers, and, most recently, healthcare, where we are developing the tools of digital cognition with a major public university’s medical school and adjacent health systems.
Recent examples of this accelerating Fourth Surge abound: A boom in AI startups including the GPT-based apps of OpenAI, the International Energy Agency’s new report on the near-exponential growth of alternative energy technologies, the historic breakthrough on nuclear fusion, further innovation of mRNA vaccines that may soon yield universal flu and malaria protection, dramatic advances in high capacity batteries, the moon-circling journey of Artemis I, and the Food and Drug Administration’s approval of slaughter-free, lab-grown chicken.
I encourage readers to crack open the brilliant book Enlightenment Now by Steven Pinker. In it, the cognitive psychologist and science author explores both the pessimism-generation of today’s news ecosystem and the technologies powering progress – from nuclear energy to nano technology to precision irrigation to genetic engineering and much more. “The innovations in the pipeline are not just a list of cool ideas,” Pinker writes. “They fall out of an overarching historical development that has been called the New Renaissance and the Second Machine Age.”
Certainly there are many tributaries to the river of innovation that is lifting our society and economy, this New Renaissance that Pinker describes. But all of them have been borne along by these intermittent surges in the evolution of the tools and computational usage of data.
So let’s explore the dynamics of these surges, these periodic bursts in the enablement of data’s use that shape the ongoing evolution of the 21st century economy:
The “first surge” traces to the embrace of data technology by banking in the 1970s
As I’ve written elsewhere, the first known commercial data – records of animal sales and grain harvests – were recorded as cuneiform by the Sumerians in ancient Mesopotamia on clay tablets around 3000 BCE. Data became a true utility in the late 15th century with the invention in Florence of double-entry bookkeeping, which provided clarity that allowed commerce to flourish and ushered in the Renaissance. But the arrival of ubiquitous data in a profound way – the first surge – really traces only to the 1970s and 1980s when its use in the banking sector began to expand as computers became more powerful and sophisticated. Banks started using data for advanced purposes, such as fraud detection and risk management. The rise of credit card systems also contributed to the growth of data use in the banking sector. And of course data use has since exploded in the financial sector in countless ways. This first surge brought manifold benefits. A study last year by the McKinsey Global Institute forecast that open data sharing in the financial sector will comprise as much as 5% of global GDP by 2030.
In an exploration of this first surge at our biannual data summit in September, Rupal Sumaria, the head of data governance for Penguin Random House UK, noted the legacy of banking’s early practices that we have yet to fully resolve. In her presentation on data governance she explained that the rigidity and notorious siloing that bedevils data use really trace to our practices begun decades ago with the rapid embrace of massive data tools by the highly regulated banking industry.
“Nobody tells you what data governance is, or what you are to be doing first,” Rupal explained. “The reason is simple. Most of the practice comes out of banking, they’ve been doing it for a long time.”
Like the apocryphal origin of U.S. rail track width (four feet, 8.5 inches) tracing back through pre-railway road specs in England, that in turn trace to the size of Roman chariots, banking defined the top-down, highly segmented rules of the data road for all to follow.
As banking defined the “first surge”, Salesforce defined the “second surge”
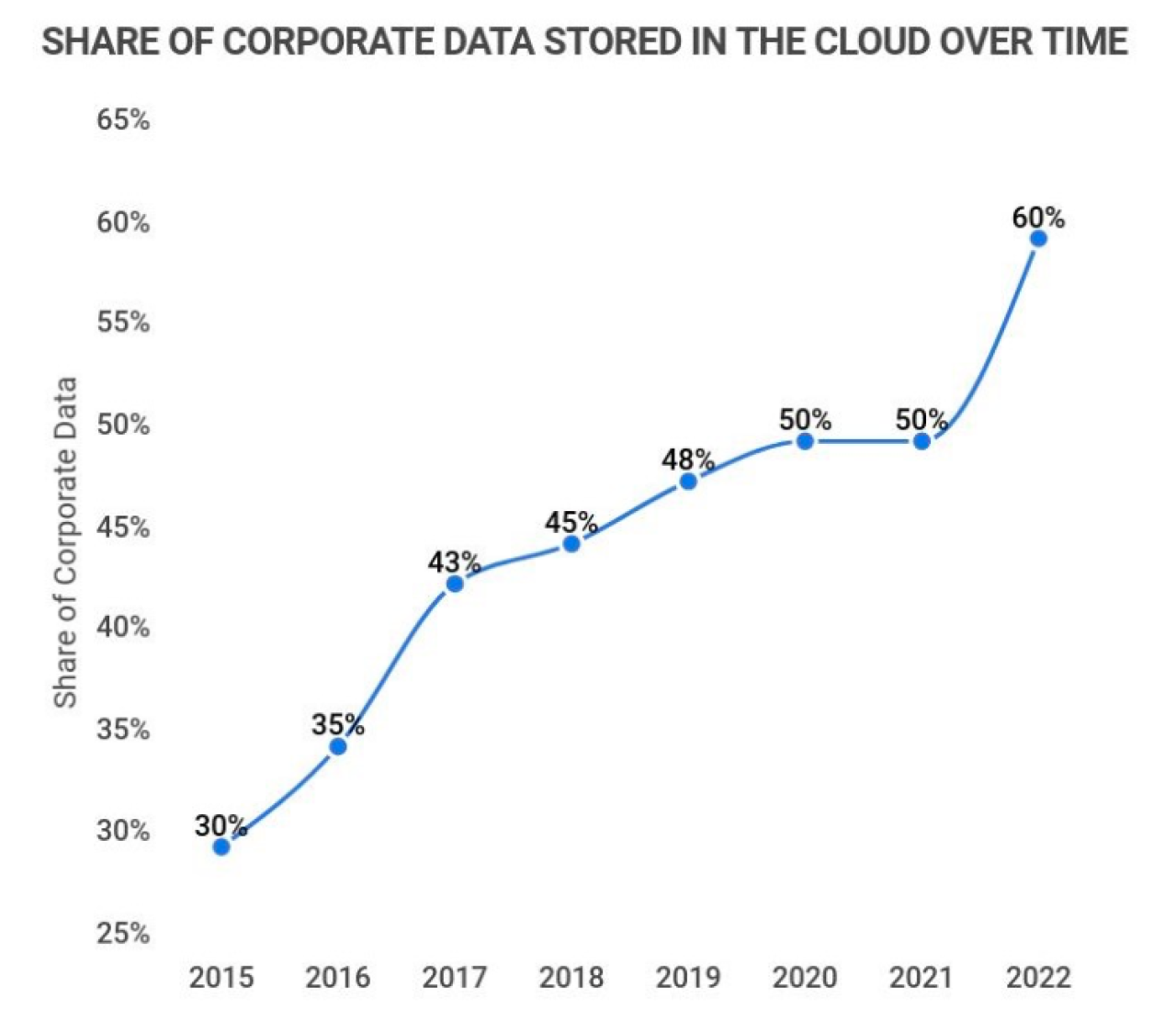
This hegemonic paradigm of data use and governance began to erode with the “second surge” that had its origin in the virtualization of computing and networked computers. Concretely, it really dates to the founding of Salesforce in 1999, the first “Software as a Service,” or SaaS, company. This set the stage for data volumes and usage to continue their exponential growth, leading to Amazon’s launch of the first data storage “cloud” in 2006. We all know the implications. Today, cloud data storage is nearing a $500 billion market. In little more than a decade it’s become a backbone of data analytics, AI, machine learning models, and IoT, the “Internet of Things” that now connects 14.4 billion devices worldwide. Some 92 percent of businesses have a cloud strategy in place or in the works, according to Zippia.com, the career mentoring site. The cloud is also used by an estimated 7.1 million cloud native developers, including those at data.world. We too are entirely SaaS and cloud-native from our foundation up.
Source: Zippia.com
The second surge liberated data in many ways, and massively expanded it as a resource. Its governance, however, remained very much in the top-down mold established in the early days of data-driven banking and finance. Data’s management and governance continued to be regimented, top-down, and rigidly hierarchical.
While necessary, the “third surge” that followed was a double-edged sword
The “third surge”, the data security industry, was long in incubation. While a critical response to data-driven criminality, it was also a double-edged sword that enabled the continuing growth of data as a resource while ironically constraining its practical utility. In many ways this surge bolstered the unresolved legacy of banking’s rigidity and siloing of data, often making it more inaccessible to those needing it.
Cyberattacks date at least to 1988 when a graduate student at Cornell University unleashed a “worm” onto the fledgling internet that was then almost exclusively the realm of academia. There were certainly others. You may remember the notorious hacker Kevin Mitnick – now a celebrity cybersecurity guru – who was arrested in 1995 and spent half a decade in prison for his breaches of multiple corporations. But counter measures to protect data remained at best a boutique industry, a sideline of IT departments. Companies fixed problems when they occurred.
This slow-moving new category in the data ecosystem was to dramatically change in 2013, however, with history’s most high-profile data hack. This was National Security Agency consultant Edward Snowden’s delivery to journalists of a data trove revealing illegal surveillance by the U.S. and other governments, often in collaboration with major telecommunications companies. Hailed by some as a whistleblowing hero, by others as a traitor, Snowden fled to Moscow where he has remained. He was granted citizenship last September by President Vladimir Putin.
There have, of course, been scores of other notorious breaches, from the 2017 “WannaCry” ransomware attack on Microsoft computers in 150 countries, to a breach last June of 2.5 million Social Security Numbers from a student loan servicer, to the theft of 5.4 million Twitter accounts a month later. But Snowden’s action stands in a class of its own, a snatch and dump of 1.7 million classified documents.
The global reaction effectively accelerated the birth of a new industry as boards and executives everywhere demanded deeper moats and higher walls around their castles of data: double encryption, firewalls, packet sniffers, network intrusion detection, distributed blockchain data vaults; not to mention rigorous background checks and polygraphs. At the time of Snowden’s deed, data security was approaching a $40 billion turnover. Last year, companies spent at least $150 billion to wall off data and the sector is expected to grow to more than $400 billion in the next four years. Stunning reports last week speculate that China’s advances in quantum computing may have cracked the standard encryption tools now used to protect data. If this proves true in practice, it will spur the sector to grow much faster.
With the rapid rise of cybercrime, the moats and firewalls are unquestionably necessary. But just like the ubiquitous searches at airports, cameras on street corners, or restrictions during the pandemic, they have come at a cost. With data under lockdown, those who need it often can’t get it, decision-making is slowed, and the teams managing data are exhausted. A survey we commissioned at data.world with Data Kitchen revealed that 97% of data engineers are frustrated and 70% are looking for new jobs. No wonder. The 1970s banking paradigm of data governance I discussed above was now reinforced like a digital Fort Knox.
As with the other overlapping surges in the last half century of data’s evolution, the seeds of the Fourth Surge were planted earlier, with the publication of the Agile Software Development Manifesto (most commonly referred to as the Agile Manifesto) by a circle of 17 creative engineers and programmers in 2001.
The manifesto birthed a developer community liberated from the top-down “waterfall” hierarchy of Dilbertesque corporations. It’s hard to exaggerate the ways their bottom-up ideas profoundly remade the software landscape. It sparked the revolution vividly described by Netscape founder and venture capitalist Marc Andreessen in his now-famous 2011 essay, Why Software is Eating the World.
Now, having lived through that transition from waterfall methods, many of those software developers have become the data engineers and scientists who are leading and inspiring an analogous transformation in data, a convergence of tools and approaches that I call the “Double Helix of Data”.
Just as the biological double helix enables the replication of DNA, bringing life to biological systems via the mitochondrial genome, the innovations of the Double Helix of Data are an equivalent force multiplier of the superorganism. This surge will profoundly usher in the coming transformation in the real economy and society at large.
In Part Two, I’ll have much more to say on the Double Helix of Data as we dive deep on the Fourth Surge.