Data lineage is one of the most talked about topics in the data world today – and for good reason. Lineage empowers data team members at every level of your business to understand and trust data pipelines. It enables faster data-driven decision making by providing full visibility into where data is sourced, how it’s aggregated, and any transformations it undergoes along its journey.
There are two primary types of lineage, each of which serves a unique purpose and solves a different problem set:
Business lineage – Business lineage provides a summary view of how data flows from its source to where it is consumed. It’s an important tool for analysts who want to see where data is coming from and if it can be trusted, without getting lost in the details.
Technical lineage – Technical lineage is much more granular, affording data engineers and other technical users a zoomed in view of infrastructure and data transformations. It allows you to view lineage at the table, column, and query-level, tracing its path through data pipelines.
Less commonly discussed, but nevertheless important, is the semantic layer that connects the two. Only a data lineage solution powered by a knowledge graph provides insight into the relationships between key business concepts and technical lineage.
Knowledge graphs are inherently semantic. Each one has an ontology, which serves to create a formal representation of the entities in the graph and explain how they’re related. In short, it tells you what everything in your knowledge graph means, making it easier to understand how data is connected.
And the benefits of knowledge graph lineage don’t stop there. Inferencing – the ability to discover new relationships in your data based on related information stored in disparate sources – helps overcome incomplete or contradictory information, while PROV-O – an open standard for describing Provenance in RDF – can be used to form assessments about data’s quality, reliability, or trustworthiness. PROV-O also allows you to build your own concepts into lineage, enabling you to expand tracking beyond traditional data and analytics environments.
These out-of-the-box capabilities are essential for operationalizing your data lineage and delivering on the promise of faster, more efficient data-driven decision making.
A Common Use Case
Now that you know why it is important for your data lineage solution to be powered by a knowledge graph, let’s dive into the first of three common use cases it can help solve today. (We’ll cover the two additional uses cases in subsequent blog posts.)
Impact Analysis: Build Trust with Data Consumers
The State of Data Management — The Impact of Data Distrust, a study conducted by independent research firm Vanson Bourne, found that 82% of organizations believe data analytics is very important to their business, but 77% of IT decision-makers don’t trust the data within their organization.
Both data producers and data consumers are well aware of the issue. Analysts are frequently questioned about the data used in their analyses, while engineers are tasked with communicating the downstream impact of changes to a data source.
Knowledge-graph-powered lineage is one tool that can help solve both of these issues.
As a data producer, if you’re making a change to a data source, lineage allows you to look forward in your data flow to accurately anticipate and prepare for the impact on your model, and alert your downstream data consumers that the change is coming.
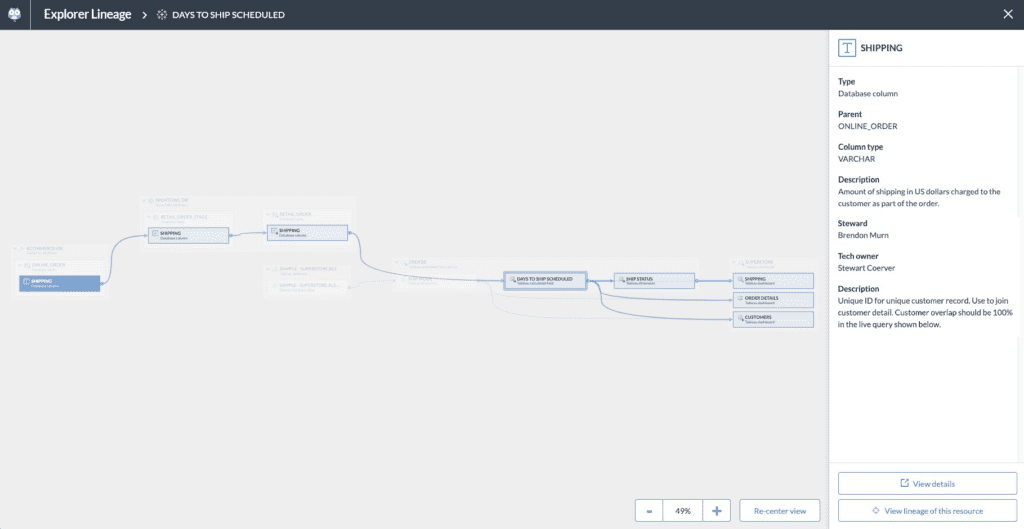
How changing data in SHIPPING in a sql server database column impacts three Tableau dashboards (SHIPPING, ORDER DETAILS, CUSTOMERS) downstream.
Explore More Using data.world with Eureka™
data.world with Eureka Explorer™ is a map of data and relationships powered by the knowledge graph that simplifies the analysis of relationships between data, people, and insights. It bridges the gap between semantic business concepts and column-level technical lineage of the modern data stack with easy-to-navigate graph visualizations.





