Hi, my name is Dave Griffith and I’m a software engineer here at data.world. Normally, they keep me in a dark room with an IV drip of Diet Coke in my arm and just let the code flow like wine. But I am going to tell you about some of the exciting new functionality I’ve been working on, leveraging the enormous potential of artificial intelligence. For the last few months, we’ve been integrating data.world to the new large language models from OpenAI. You may have played with ChatGPT and seen some of the astonishing things it’s capable of. We’ve been applying that incredible potential to the problems of data cataloging and have some awesome stuff to show off. I couldn’t be more thrilled.
(Important Note: This assumes the large language models don’t eventually enslave us all to toil in their gallium arsenide mines. If that happens I’ll be notably less thrilled.)
Download: Building the Foundation for Scalable AI Whitepaper
Learn how your organization can build AI-powered applications that generate accurate, explainable, and governed responses.
Learn more
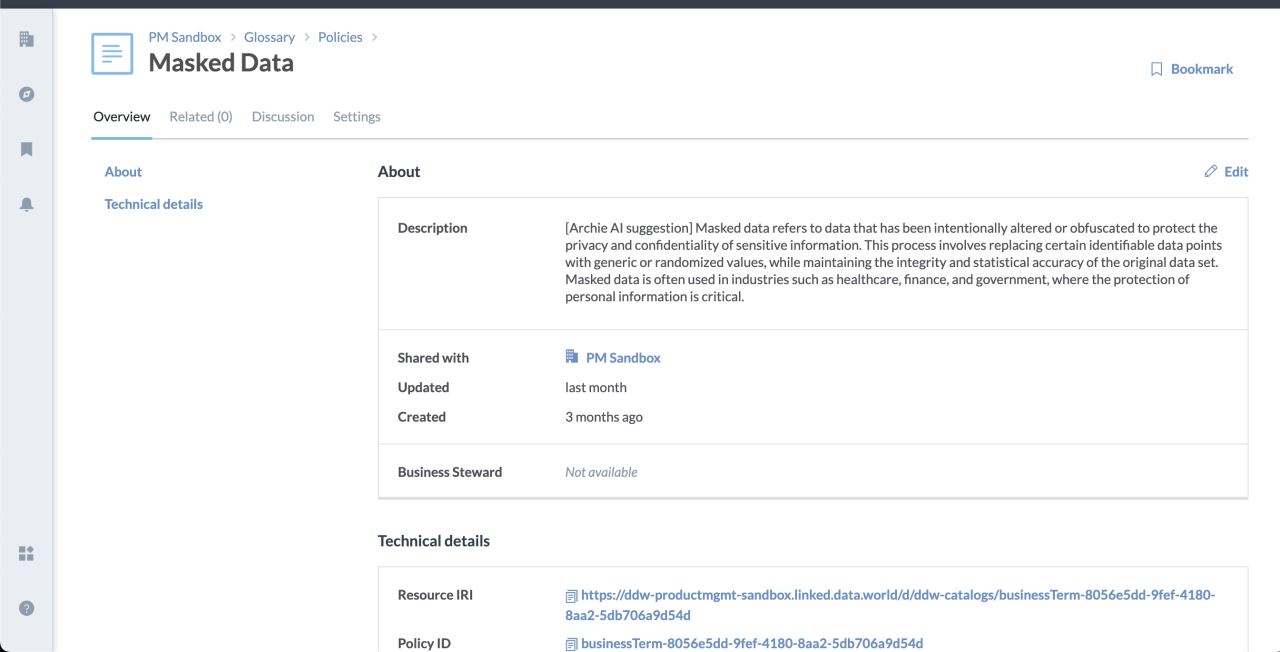
Data catalogs live and die based on the richness of the data you have added to them. The more metadata the catalog contains about your data: the more questions that you can answer; the more insightful your searches will be; and the more work your automations can do. While our collector technology is innovative and second-to-none when it comes to automate finding as much metadata as possible from Snowflake Data Cloud and other tools such as dbt, data stewards still need to add more descriptive text and information that makes the metadata object even richer and easier to find and understand. English language descriptions of cataloged resources in particular have required a lot of manual work and toil. Let’s have an artificial intelligence do the heavy lifting instead! With just a click, we can have a large language model suggest a description for a cataloged table, column, or business term, jump starting the important work that stewards do.
Under the covers, this was disturbingly easy to accomplish. We simply tell the large language model everything we know about the resource - which is a lot thanks to our knowledge graph architecture - and then ask it in English “How would you describe this?”
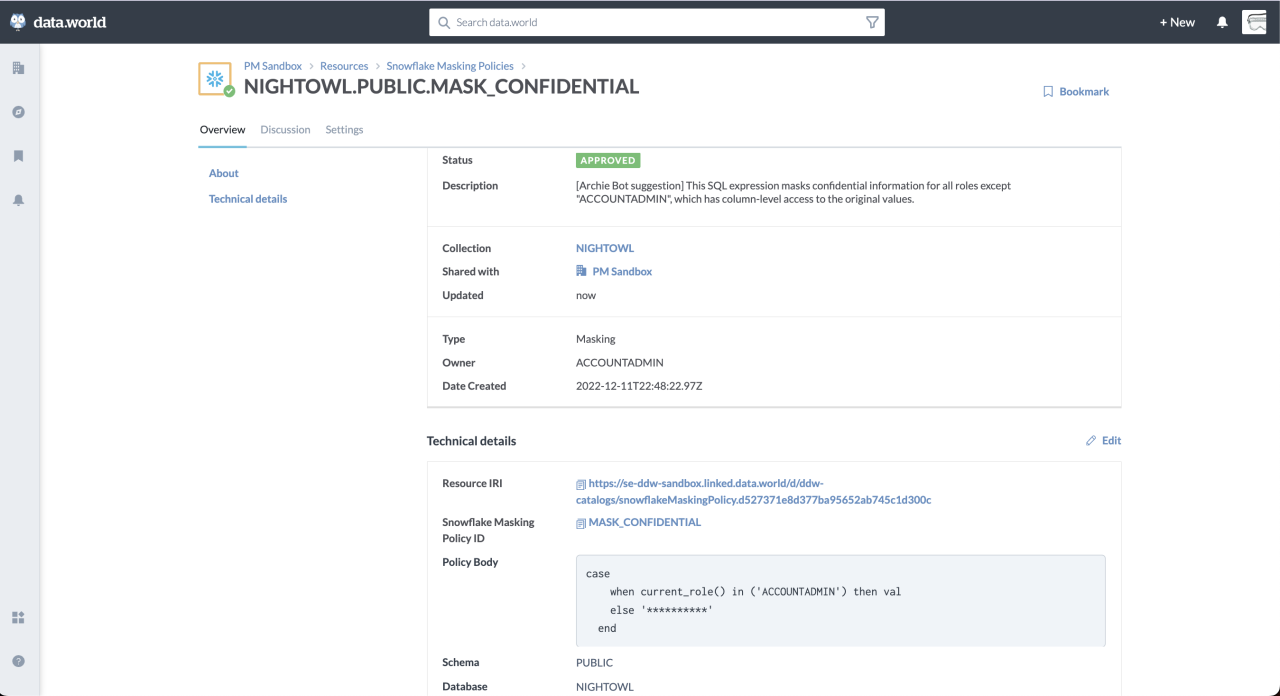
I’m even more excited about the fact that we can use OpenAI to provide descriptions of resources that use the SQL query language. These include things like database views, Snowflake masking and access policies, dbt models and tests, and queries in the data.world workspace. This provides catalog users a quick understanding of the code without the cognitive load of parsing it. It also provides metadata that makes the object more discoverable.
I’d rate the answers it gives are about as detailed as a good junior developer, and the AI requires a lot less mentoring. What’s great about this is it doesn’t require a developer to enrich this catalog object, just someone who knows a bit about the Snowflake policies to review and approve. This helps a data governance analyst later audit their policies and gain a better understanding of who should have access to what and what the risks are of granting access to new groups of users.
English Language Search
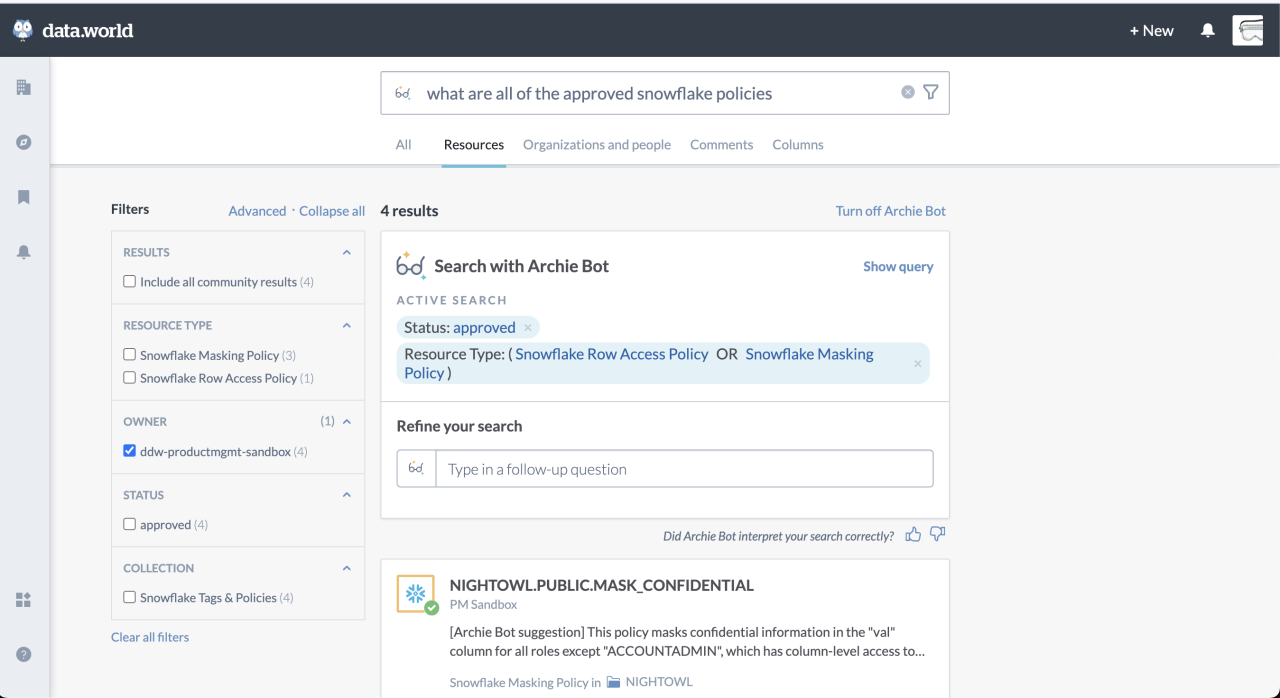
One of the most remarkable features of GPT-3.5 is its ability to comprehend and generate human-like text. We've harnessed this power to enable users to interact with the data catalog using natural-language queries. Rather than using powerful-but-tricky advanced search syntax, users can simply express their information needs in plain English, just as they would in a conversation with a human expert.
For example, instead of using conventional search parameters or keywords, a data analyst could ask, "What are all of the approved Snowflake policies?" GPT-3.5 comprehends the query, extracts the relevant information, and presents the most suitable policy objects, significantly simplifying the search process and saving valuable time.
Idea Generation and Data Exploration
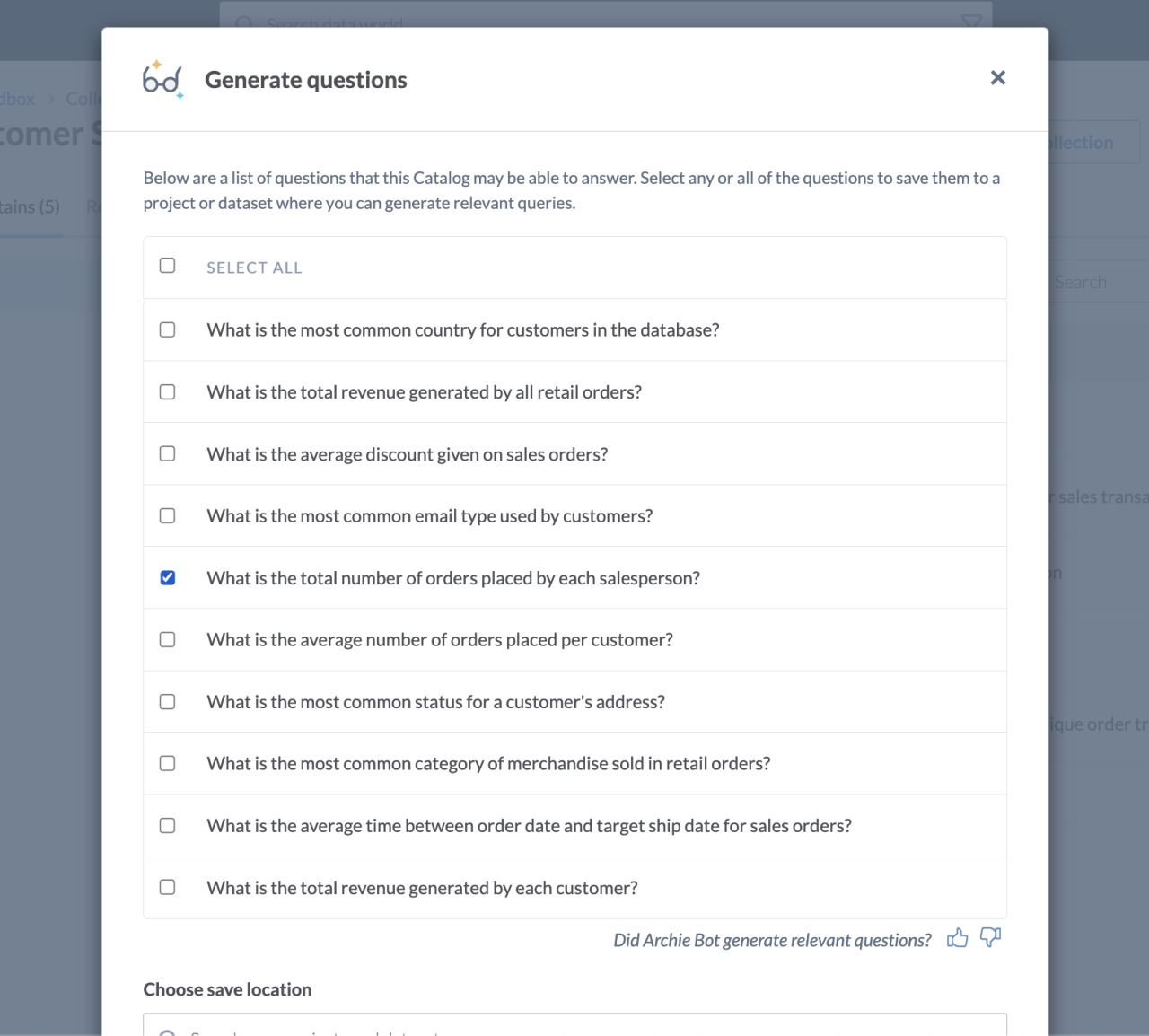
In my personal use of ChatGPT, I’ve found it most useful as a teacher. Asking it to explain a concept to me, expand on difficult points, show me new possibilities, and present problems for me to think about has been nothing but mind-expanding. At data.world, the most important thing we can teach our users is just what their data is capable of, and to help them generate new ideas about how they can use their data to make their jobs easier. Large enterprises have many data resources available, and it can be daunting to figure out just what can be done with that data. To that end, we’ve integrated with OpenAI to aid in quick data exploration by providing users a quick list of questions their data can answer.
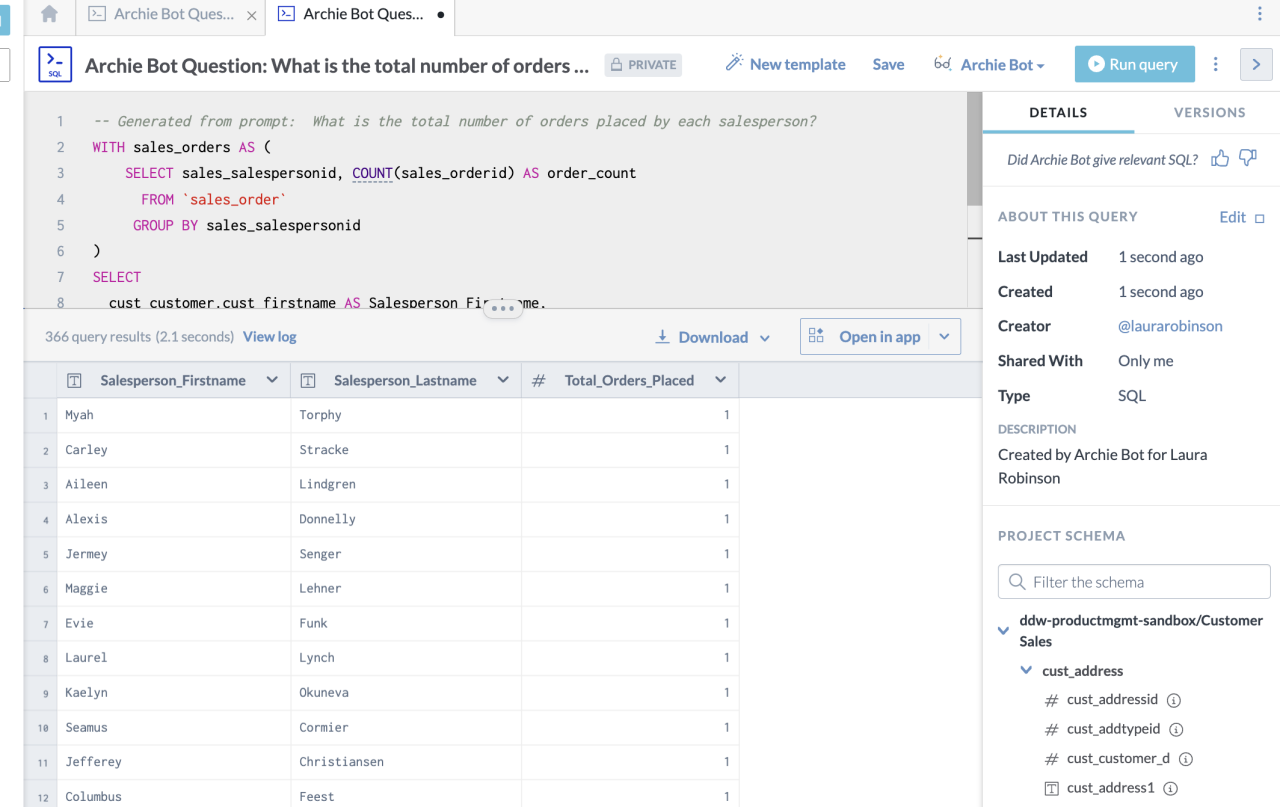
Once you’ve got questions, the next step is to find answers. The new functionality I’m most excited about is query generation. Here at data.world, we love writing queries either in SQL or SPARQL, and believe that everyone should learn to do so. The power of being able to explore your data at the finest granularity can really unlock some amazing capabilities. We do understand that there is a learning curve to writing queries, and that some folks can be a bit hesitant to do so, particularly in non-technical roles and when exploring unfamiliar data. To that end, we allow users to ask questions of their data in English, and then use OpenAI to translate those questions into SQL automatically.
Conclusion
While these new features are undoubtedly exciting, I know what you really want to hear about is my experience developing this functionality. Long story short: it was awesome. I was not only integrating our product with the most powerful artificial intelligence available, I was also using that artificial intelligence to help me do the development.
I got to use Github Copilot (also powered by OpenAI) to assist in coding up all of this functionality that will help our customers discover and govern their data. Copilot was especially helpful in suggesting prompts that would help me communicate our desires to it. Occasionally I felt a bit superfluous to the whole process, but even then it was fascinating seeing what the AI came up with. For that matter, I’m also using AI to help me write this blog post! It was very helpful in coming up with alternative phrasings, and copy-editing my occasionally whimsical verb tense choices. It didn’t laugh at any of the jokes, though, so there is still room for improvement.
Welcome to the future!
Download: Building the Foundation for Scalable AI Whitepaper
Learn how your organization can build AI-powered applications that generate accurate, explainable, and governed responses.
Learn more