Three blocks from the office, Lisa’s phone buzzes with a new alert: High correlation detected.
She races back to her desk and inhales the auto-generated report. She can’t believe it found something this quickly. Is it a mistake? Just this morning she uploaded her dataset, the product of three long months spent sampling and compiling data from 50,000 leukemia patients in the US.
Scrolling through the report Lisa sees the boundaries of one cancer cluster line up almost perfectly with a table in a dataset about the geographic distribution of avocado orchards. No, not a mistake. This is real. And that’s not the only link.
Lisa’s fingers trace two trend lines across her monitor in disbelief. One line represents the number of media references to a rare fungus ravaging avocado trees. The other line is from her own leukemia diagnosis data. Same geography. Same date range. They trend upward at exactly the same rate.
Serendipitous connections happen when data exists in an interlinked network.
Just as the World Wide Web connects documents, which contain information rendered in human-readable natural languages, the web of the future will connect data.
Concepts described in machine-readable datasets will link to other data via common references — just as web pages are connected by hyperlinks, the navigable references to other pages. People and machines will follow these connections as easily as we browse the web today.
Put another way:
The Semantic Web is about two things. It is about common formats for integration and combination of data drawn from diverse sources, where on the original Web mainly concentrated on the interchange of documents. It is also about language for recording how the data relates to real world objects. That allows a person, or a machine, to start off in one database, and then move through an unending set of databases which are connected not by wires but by being about the same thing.
– Semantic Web Activity Page
This isn’t a futuristic fantasy.
That quote? It’s from 2001. Linked Data, or the Semantic Web, both refer to the same basic concept: we can connect data using the same architecture that powers the web. The technology has had extensive academic R&D over the last couple decades, and is already successfully deployed within large organizations that amass huge data assets — Google’s Knowledge Graph and Goldman Sachs’s Data Lake are examples of companies harnessing the power of linked data within private networks.
The push to apply this technology to the entire web isn’t exactly a fringe movement, either:
When you connect data together, you get power in a way that doesn’t happen just with the web, with documents.
– Sir Tim Berners-Lee (from a 2009 TED talk)
This is the guy who invented the web, saying “you ain’t seen nothing yet.”
If this technology exists, is mature enough to use, and is supported by one of the most influential people in the web community, why hasn’t it caught fire? What has kept it out of the mainstream?
Those of us old enough to remember the early days of the web will remember a time when converting documents to HTML and publishing them using the HTTP protocol was not the de-facto solution that it is today. The web, too, was an esoteric, academic technology with seemingly no use beyond the Ivory Tower.
Authoring HTML was vastly more difficult than writing plain text. There were no tools making it easy. Sharing documents over HTTP required technical know-how that very few people possessed. Sure, there were competing technologies like FTP, Gopher, and Usenet. If HTML was the great unifier, it wasn’t obvious at the time.
Tim Berners-Lee invented the web at CERN as a pragmatic solution to a real problem: information sharing between a tiny collective of scientists working across the globe. The first hundred thousand or so documents on the web were put there with considerable effort, and the benefit of participating in that “tiny” early web was close to nil compared to that of today’s web.
The catalyzing moment: when the true cost of sharing research information became too much to bear, innovation was the only path to a better solution.

Data from
Measuring the Growth of the Web (June 1993 to June 1995)As with any network effect, the value of the network increased exponentially as the size of the network increased, and the costs went down as the tools improved. The advent of web content authoring platforms (e.g., WordPress, Medium) and social media reduced the costs to, essentially, zero.
I could hand-write the HTML code for this article, and I could run my own HTTP server to respond to web requests for it — but why would I? This way, I only need to focus on the content. Anyone who can type words and click “Publish” can add information to the web.
The scope and influence of the web reached far beyond the imaginations of its innovators to become what it is today.
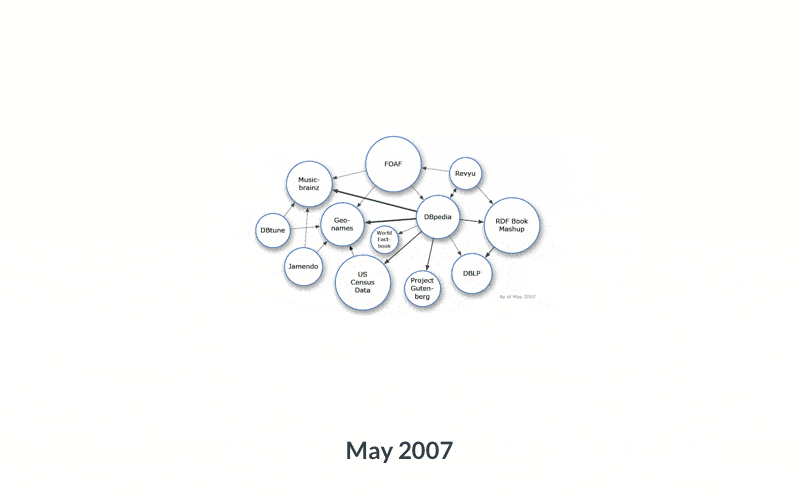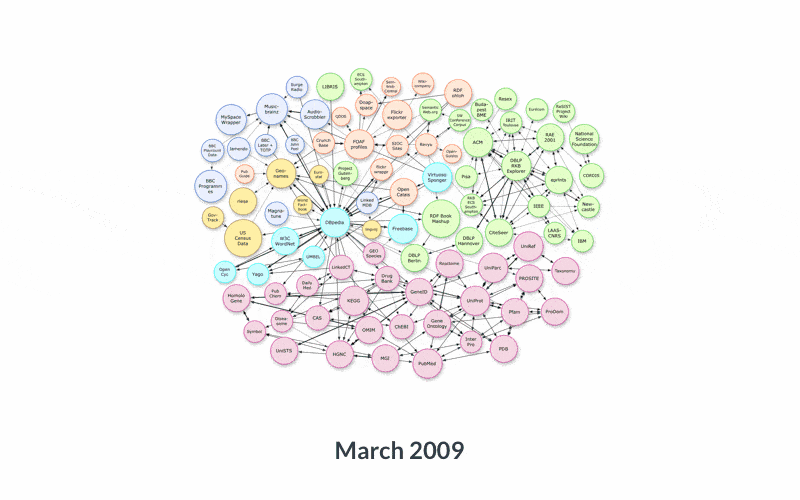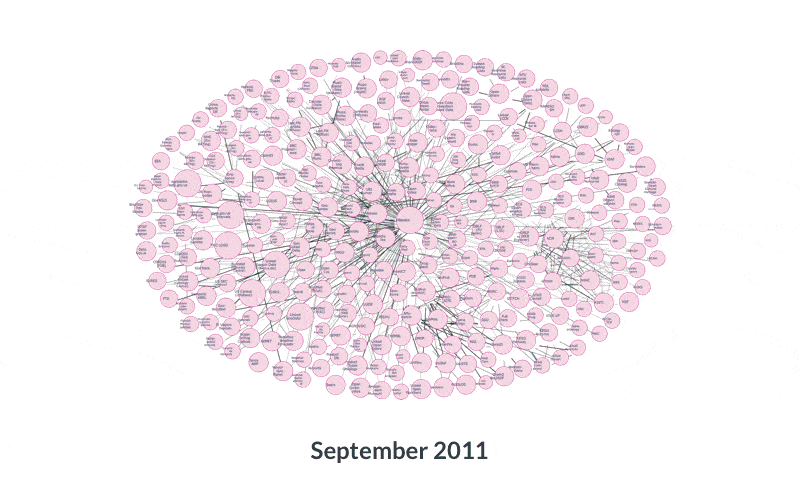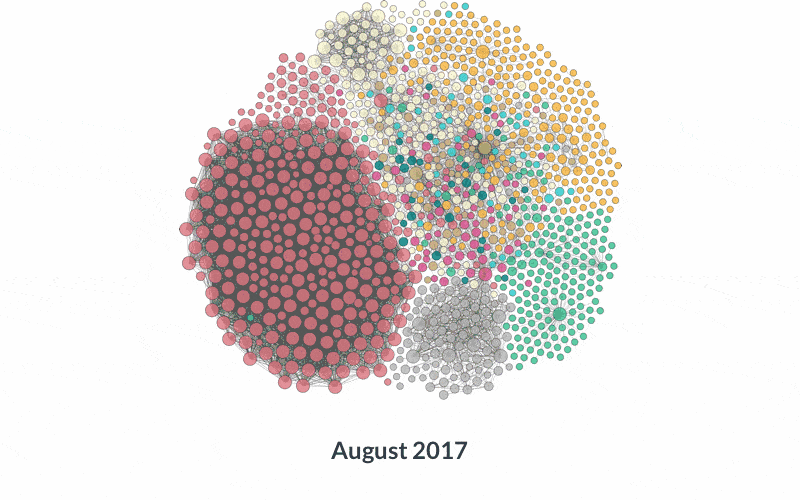
Growth of the web of Linked Open Data — images from
https://lod-cloud.net/Linked Data is at a similar inflection point.
Many of the same dynamics are at play:
The volume and diversity of data being created is leading to a crisis, a catalyzing event: the effort required to make data interoperable is consuming way too much of the energy spent in data work. This is similar to the crisis of information sharing felt by Tim Berners-Lee and his colleagues at CERN that led to the adoption of the early web
Increasingly, organizations and individuals are looking for solutions to make sense of the data explosion, and Linked Data is perfectly designed to power those solutions
The web of Linked Data will continue to grow exponentially, not linearly — so each of these new steps will only accelerate the movement further
A new set of tools will emerge to make the publication of Linked Data something that can be accomplished without having to become an expert in the underlying mechanisms of the Semantic Web. This is the “flywheel” effect, where the network of Linked Data will simultaneously get more valuable and cheaper to leverage
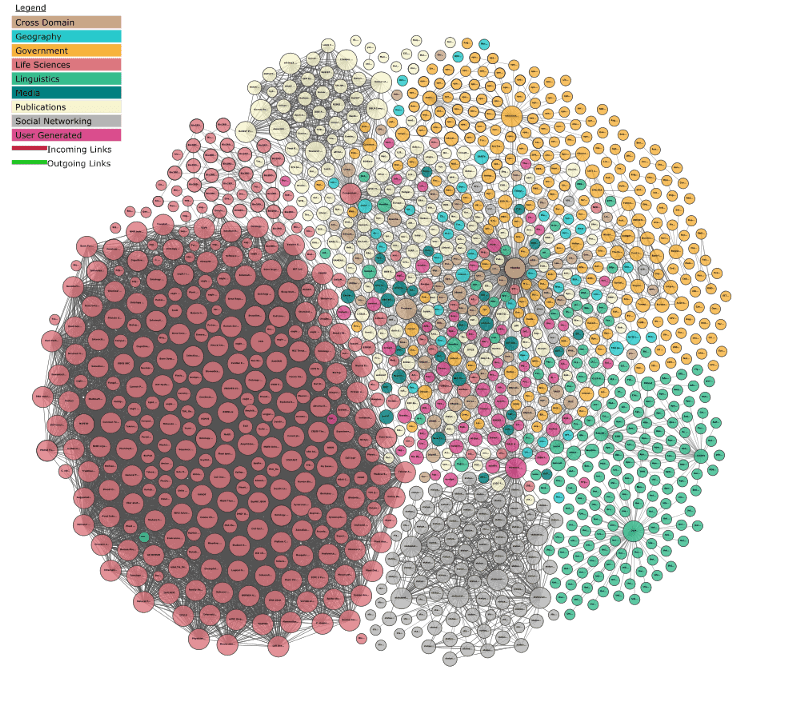
Linking Open Data cloud diagram 2017, by Andrejs Abele, John P. McCrae, Paul Buitelaar, Anja Jentzsch and Richard Cyganiak — from
https://lod-cloud.net/The web of Linked Data is the natural evolution of the web, growing exponentially and adapting to the new models of information processing that have arisen as we’ve become more connected. The web has put previously unimaginable information resources in the palm of our hand and generates staggering amounts of data, pushing us to develop new ways to use this abundance to understand our world. Modern data science practices, especially artificial intelligence and machine learning, also drive us to reshape the way we share information on the web.
An enterprise data catalog is uniquely equipped to support this future. Not sure what a data catalog is? Read this blog to learn more.
Linked Data will power a lot of that. Using data will be like browsing the web — because it will be browsing the web.
There’s a place for everyone in this evolution. Some will prefer to understand the underlying technologies (RDF, SPARQL, and OWL are all worth learning if you want to get ahead of it). Many more will experience Linked Data through the familiar language and patterns used by mainstream data workers. More still will benefit from Linked Data without knowing anything about it, just like you’re not thinking about the array of technologies that make it possible to read this very sentence.
The dream of Linked Data will crystalize while the technology fades into the background, just as it should. And once again, a decades-old idea will quietly change the world.
Learn more about the power of Linked Data in this white paper.






