The only thing more impressive than the speed at which new technologies and methodologies are invented and adopted in the data industry is the amount of chatter produced about them. And over the past 10 months or so, there isn’t much that’s been talked about, written about, shouted about, and debated more than the concept of data mesh.
There's debate about what it is. There’s disagreement over why you would want one. And there are infinite opinions on how to implement one.
So in this blog post, I’m breaking it all down and giving you a clear, simple, and informed answer to all those questions.
What is a data mesh?
Data Mesh is an architectural pattern that describes which components of your data infrastructure should be shared, and which should be distributed, in order to best facilitate the development and distribution of data products. Implementing a data mesh is an organizational and operational challenge at least as much as it is a technical one — it starts with inventorying the data assets you already have.
So, data mesh is an architectural pattern.
Taking a step back to see this in a broader context: System architecture is a way to capture the decisions you make about how a system works. Nearly every design decision in a system represents a tradeoff between several viable options. And documenting a system's architecture — via the process of writing down those decisions and their justifications — helps people understand what rules they have to follow, and why they are in place.
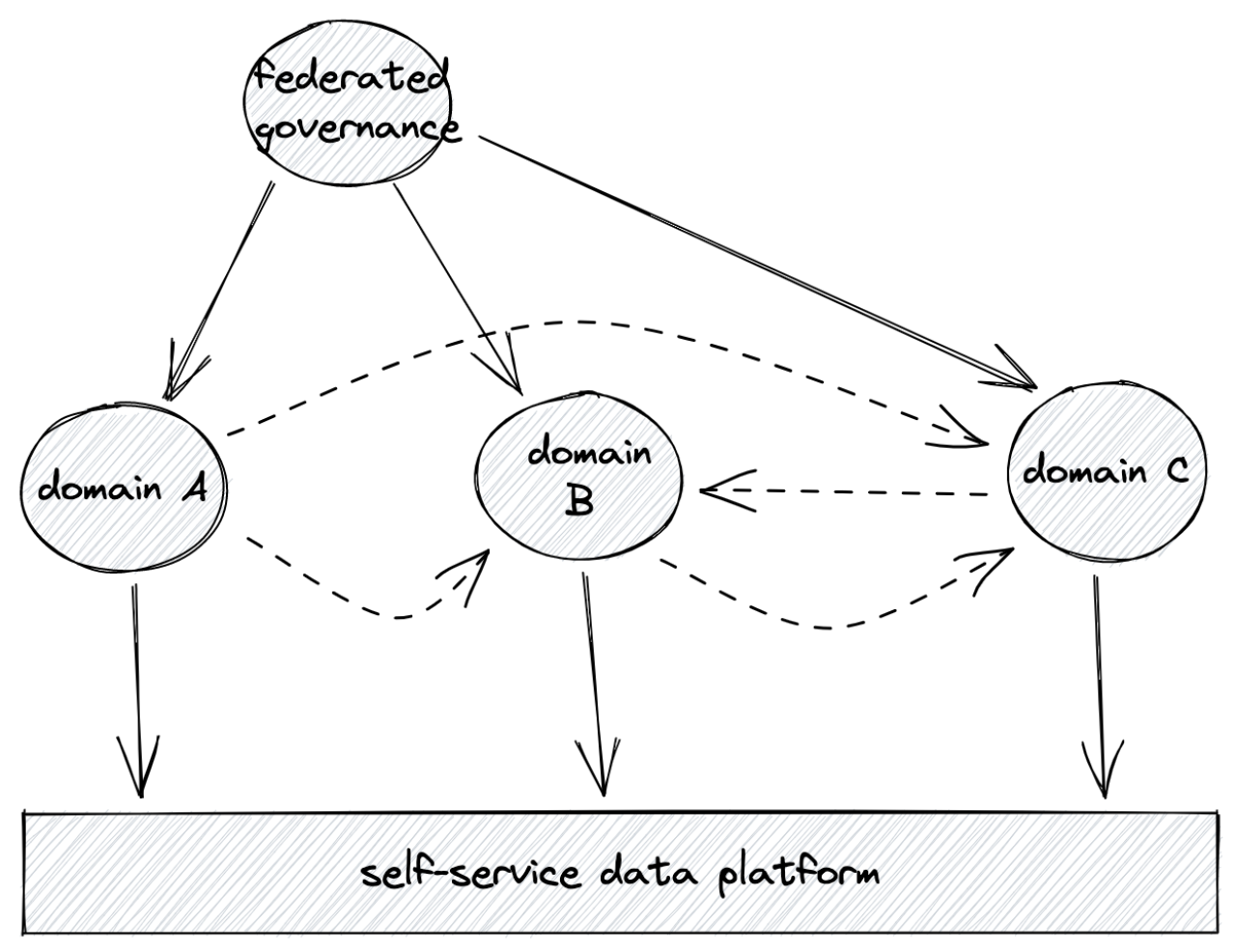
The fundamental tradeoff being made in a data mesh architecture is "what parts of my data ecosystem should be developed centrally and shared by all, and what parts should be delegated to distributed domain teams." Too much centralization and the system is slow and difficult to change — you’re not agile enough. Too little standardization, and you end up with disconnected and incompatible silos that painfully "agree to disagree" about too many things to effectively work together.
In a data mesh architecture, two things should be centralized:
This should provide the domain-independent capabilities for data collection, management, distribution, and analysis, as a service to the owners of various domains.
A federated data governance program.
Issues of regulatory compliance, adherence to industry standards, and enforcement of enterprise-wide policies should be handled by this function. It exists to ensure interoperability between and governance over the various domains.
What should not be managed centrally:
Treatment of data as a product within various data domains.
The experts within each domain are responsible for building high-quality, stable products — compliant with the federated governance, and provided as a service to consumers in other domains using the self-service data architecture.
Why build a data mesh?
The goal of building a data mesh is to facilitate the development and distribution of data products. What are the characteristics of a data product?
It's a dataset that has been prepared for a particular use or class of uses, with the structure of the data optimized for consumption in those cases.
It's treated like an API — a functional contract between the producer and consumers of the data, allowing the consumers to confidently build applications on top of the data products.
The metadata for the data product is a first-class concern — the data product is self-describing and makes it easy to know what the data product is about and how it is meant to be used.
The domain team also maintains an operational contract for the product, managing availability, quality, and freshness.
When your data is managed like this, your data consumers have a clear path to getting value from data, and they can build applications and analyses with confidence based upon the catalog of data products published from the various domains.
We’ve seen this movie before
So now you know the idea of data mesh is to architect your data systems (incorporating people, process, and technology) to treat data like a product and properly realize the value of your data assets. The main points of the architectural pattern are:
Distribute control of data along the lines of data domains
The topical experts within each domain control the data in that domain, and make the decisions about how that data is to be modeled, and what data products should be published to consumers outside of that domain.
We don't want to saddle these domain owners with the operational responsibilities to stand up technology. Instead, build a shared infrastructure that everyone can consume as a service, and empower domain owners to leverage this shared infrastructure to distribute their data products.
Deliver data as a product
Share data with clear interfaces and documentation, like APIs for software products. Data products should be "packaged" to make discovery and consumption easy. Metadata and semantics should be clearly provided alongside the data, and the goal should be to make sure that the people who need the data can find out about it, understand how it fits their use case, and operationalize it as easily as possible.
Maintain federated data governance
Some things have to be centralized in order to maintain regulatory compliance, adherence to industry standards, and in general interoperability between data from various domains
There's another system that follows exactly these same patterns, one that everyone is familiar with and uses daily: the world-wide web. Looking at the parallels can help understand why a Data Mesh is so powerful.
Distributed ownership of domains
The Web is fundamentally designed for distributed ownership, via domains. If you want to put up a new website, one of your first stops is to acquire a domain name — say “example.com” — where you will host your content. When you use the web, you're accustomed to referring to content with URLs (Uniform Resource Locators), which look like “http://www.example.com/my/content/page.html”. The anatomy of that URL is:
A "scheme" (http in this case) which tells a client program what protocol to use to access the resource.
Followed by the "domain name" (www.example.com), which routes the client to a server specified by the owner of that domain.
And finally, the "path" (/my/content/page.html) which is a specific name for the resource to retrieve, unique within that domain.
In this way, once you have acquired a domain, you are in control of what resources are published under that domain. On the Web, you publish web pages and other content; in a data mesh, you're publishing data products in your domain.
The web operates as a distributed network of computers — requests flow from clients to servers, and responses flow back to clients, all using a shared infrastructure. This all works because there's a clear and well-defined protocol (HTTP) that web software uses to standardize and facilitate this communication. There's a shared platform that anyone can use to consume websites, provided you have an HTTP client. And anyone can publish to it on an HTTP server.
This is the point of the self-service data platform in a data mesh; By standardizing the foundational technologies, we empower data producers and consumers to share high quality data products in much the same way the web empowers content providers and consumers to interact at massive scale.
Deliver data as products
The contents of the web are documents and applications. These are assets designed primarily for human consumption; documents are read by people, and people interact with applications through their user interfaces. What do these applications and documents have in common? They're implemented in HTML - a standard language for representing the contents of documents and the user interface for applications - which means that they can be displayed and interacted with via standard clients, called browsers. Consumers of these assets don't have to think about this - moving from one web application to another is as easy as following links, the browser makes sense of it all - and it knows how to do this because of the combination of HTML and HTTP that are at the core of the web.
If you understand the Web, you understand data mesh
Now you can see, the concept of a data mesh isn’t as foreign as you might have thought. Like the Web, a data mesh distributes control of data along the lines of domains. Like the web, a data mesh constitutes a shared infrastructure that everyone can use to both consume and distribute their data products. Like the web, a data mesh relies on “data products” to make discovery and consumption easy (with metadata provided alongside the data). And like the web, a data mesh adheres to industry standards to enable general interoperability between various domains.
If you want to see an example of data mesh in action, check out this case study with data.world customer OneWeb, a communications company building a 700-satellite constellation to provide global satellite Internet broadband services to people everywhere.