Big data has revolutionized the business world. Since the phrase “big data” first rose to prominence in the early ‘00s, numerous studies have shown that businesses focused on using data and business analytics to inform their decisions are significantly more productive and successful than competitors that don’t.
The amount of data collected since the dawn of the big data era is massive, with total enterprise data volume now standing at near 2.02 petabytes. (For reference, a Petabyte is an enormous amount of data, the equivalent of 500 billion pages of standard printed text.)
The challenge for businesses is no longer collecting this data, but governing it: finding exactly what’s needed, understanding what it means, then using it to drive business value. To do this, enterprises have turned to DataOps, a collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across their organization.
According to Forrester Research, the broad adoption of DataOps mirrors the overarching business trend of moving away from centralized, siloed governance models and complicated data applications, toward increased democratization of data and user-friendly, self-service data products. Companies are also implementing DataOps to break down barriers between historically siloed IT and business teams, and focusing on “obsessive collaboration” with the goal of lowering time to value for business stakeholders.
To Enable DataOps, You Need a Data Catalog
There’s no technology you can adopt that will immediately establish a DataOps methodology, but the right tech enables DataOps within your enterprise. And no piece of your data tech stack is more critical to establishing DataOps than an enterprise data catalog.
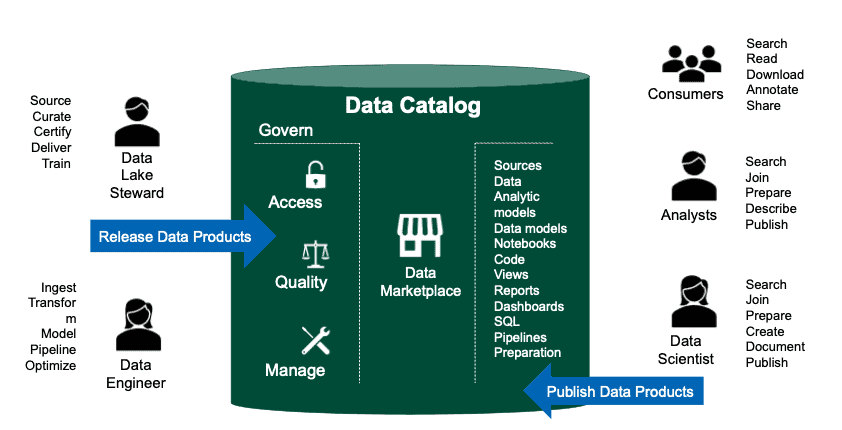
First and foremost, a data catalog helps you manage your data and analytics product portfolio.
It also:
Improves communication, integration, governance, and collaboration by automating the flow of information between data producers and consumers.
Enables data transparency and empowers data engineers to develop, coordinate, and orchestrate data policies and controls.
Facilitates continuous integration/continuous delivery of data for faster time-to-value.
Aligns data and analytics products.
Provides a centralized library with ready-to-use and -reuse components in terms of datasets and queries.
And most importantly, it enables data governance by design, a mandatory requirement for organizing and running a data-driven organization. All of these capabilities combine to serve the wider goal of transforming data into value.
Data Catalogs Play a Central Role in Data Value Delivery (Image courtesy of Forrester Research)
What to Look for in an Enterprise Data Catalog, According to Forrester Research
In our July 14 webinar, “Why you need a data catalog for DataOps” — which data.world VP of Product Tim Gasper co-hosted with Raluca Alexandru of Forrester Research — Raluca listed the functionality and capabilities required of an enterprise data catalog being used to lay the foundation for a DataOps methodology.
First, the catalog must be able to address diverse, granular, and dynamic data and metadata in order to provide transparency on the nature and path of data flow and delivery. An enterprise data catalog with this capability must be built on a knowledge graph, which allows for the cataloging of any data asset, not just rows and tables within a database.
To enable “obsessive collaboration” between data producers and data consumers, the catalog must also be built with a user-friendly UI/UX that’s easy to understand and navigate, and supports and reinforces modern DataOps and engineering best practices.
It must enable continuous integration/continuous delivery of data to drive faster time-to-value and meet the expectations of business stakeholders.
It must also be able to manage data and analytics products. Composable architectures and AI capabilities, which, with federated data government, can become chaotic without the right tool; a data catalog organizes your data ecosystem, aligning data and analytics products while providing a centralized library with ready-to-use and -reuse data and query components.
Lastly, it must empower your organization to govern data by design, which is a mandatory requirement for organizing and running a data-driven organization.
A Data Catalog Is the Foundation of Your DataOps Stack
As businesses move towards a DataOps methodology and move away from centralized, siloed governance models toward increased democratization of data and user-friendly, self-service data products, enterprise data catalogs will continue to play an ever-greater role in data value delivery.
As the technical platform that supports all the capabilities and a marketplace for business users to find the data they need, a data catalog should be the center of your data architecture and the foundation of your move toward a truly data-driven culture.





