When a team or individual within your enterprise owns data in the same way a team owns a product, i.e. the set of services that implement a facet of the business they support, and they treat other teams as internal customers of that data, you’re treating data as a product. These teams or individuals act as data product managers, serving as the bridge between data producers and data consumers, and making sure data satisfy the requirements of internal users. But what is a data product as it relates to data mesh?
What are Data Products?
As we’ve mentioned on the data.world blog, a data mesh is an approach that empowers domain experts to own the data they create and make it available to consumers across business lines. It is defined by four pillars: data ownership by domain, data as a product, self-service data, and federated computational governance.
According to Zhamak Deghani — originator of the phrase “data mesh” — the data as a product archetype is an integral component of a data mesh architecture, and it’s essential for making data governance more scalable across broad parts of a company. Treating data as a product means bringing product thinking to data management, already a common practice in software product development. But what does this look like in practice?
A data product is a reusable data asset, built to deliver a trusted dataset, for a specific purpose. It collects data from relevant data sources — including raw data — processes it, ensures data quality, and makes it accessible and understandable to anyone who needs it to meet specific needs. Data products are analyzed by data scientists and analysts to inform predictive analytics, build data models, build new reports, assist in machine learning, and more.
A data product makes a dataset easier to understand, easier to discover, and easier to access as a data asset. It generally corresponds to one or more business entities — customers, orders, etc. — and is made up of metadata and dataset instances.
When building data products, a data product manager gathers requirements and use cases, and learns the specific needs of end users to define a roadmap and plan. The data product team executes on the plan, and tests, releases, and iterates in an agile fashion to improve that product, continually enhancing data assets and data quality with every iteration.
Data consumers can then use these data products to create business intelligence dashboards and reports, and data teams can run artificial intelligence and machine learning models to improve business decision-making and gain a competitive advantage. Data analysts, BI developers, and data scientists are examples of data consumers.
An Example of Data as a Product
Some examples of data products are datasets, data streams, data feeds, or APIs; code or data models; analytics models; and dashboards.
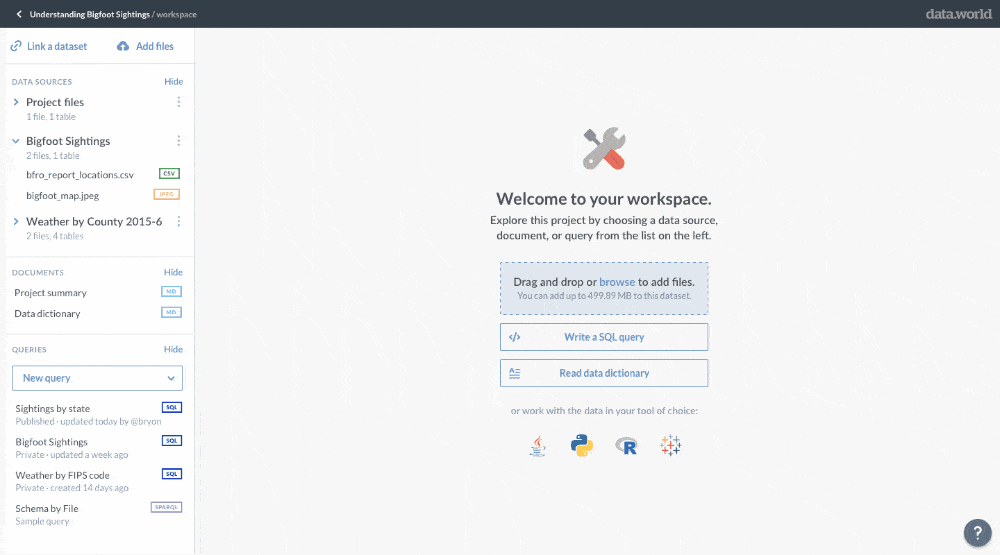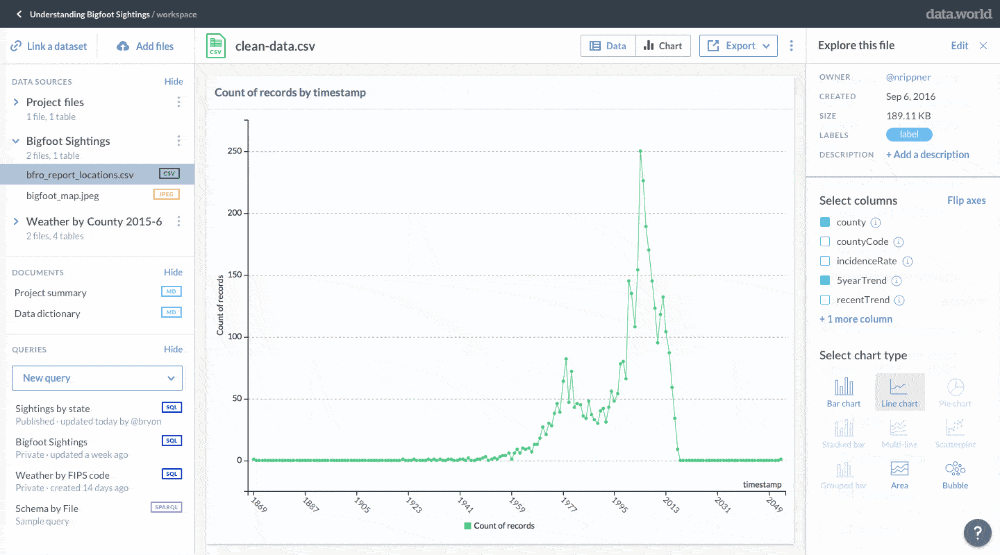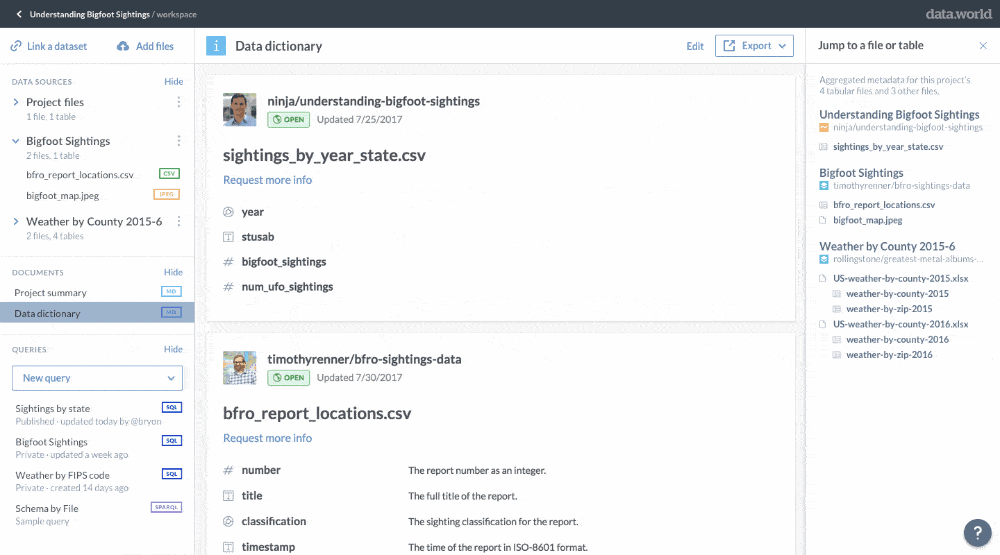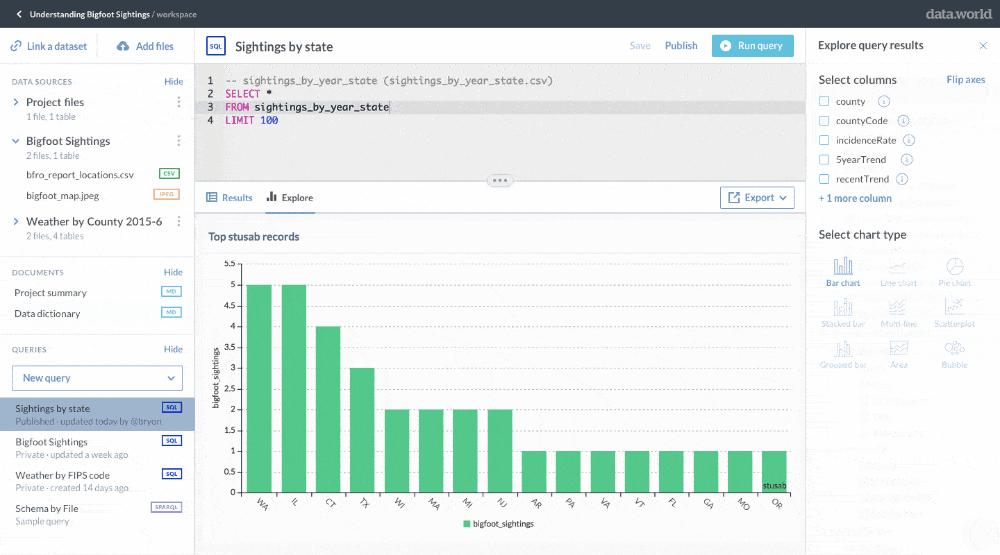
Dashboards that provide useful metrics or easily understandable types of data visualization — like the Google Analytics dashboard or many of the digital products empowered by Tableau — are good examples of the use of data products as mentioned above, as they empower even non-technical users to gain valuable insights via subsequent data analytics.
Benefits of Data Products
Organizations that adopt a data mesh approach to data management and build high-quality data products see improved efficiency, collaboration, and data democratization, and their product and data teams are generally better informed as to the value and end use of data.
Teams that use data products spend less time searching for data, ensuring data quality, or building new data pipelines, and those time savings become significant when added up across your data ecosystem and lifecycle.
Additionally, data products speed time to insight because they can be reused and repurposed, increase trust in your organizations’ data, and provide real-time data for in-the-moment decision-making.
How to Create Data Products
At data.world, we’ve spent a lot of time thinking about the best way to go about deploying data products, and we call our method ‘The Data Product ABCs framework.’
This framework provides insight into the types of questions data leaders should be asking when developing data products. These include questions about:
Accountability – e.g., “Who’s responsible for this data?”
Boundaries – e.g., “What is the data?”
Contracts and Expectations – e.g., “What are the sharing agreements, consented uses, and policies?”
Downstream Consumers – e.g., “Who are the current consumers?”
Explicit Knowledge – e.g., “What is the meaning?”
Additionally, domain teams must maintain a consistent and usable interface to their data. Consumers should agree on the style of the interface as it pertains to their needs: well-defined tabular structure, API endpoint, SQL or SPARQL interface, Parquet, Graph, etc.
What’s most important, regardless of the interface, is that the semantics – underlying logic – of the data products are the same. This includes keeping the Contracts and Expectations in place and notifying producers and consumers if something goes wrong.
Future of Data Products
As a critical aspect of a data mesh approach to data governance, data products empower organizations of all kinds to leverage data to achieve business success. And as data mesh itself becomes a more commonly accepted best practice for enterprise data management, the ubiquity of data products is sure to increase.
If you’re interested in adopting the advantages of treating data as a product for your enterprise business, download the Data Product ABCs Worksheet.