Frequently when I demo data.world at conferences, meet-ups and customer meetings, I get asked “What can I put in data.world?” It’s easy to look at the platform and assume that it’s like a database (it can be one those) or a project management platform (it can also be that).
So what do you put in data.world? Our philosophy is that all context should be kept as close to the data and analysis as possible. That’s why a data.world dataset or Data Project can contain so many different file types (and then we treat the stored file in the most data-aware manner possible). When asked the question, I frequently say that there are 4 levels of data and context that go into data.world to make collaborating on data easier:
Level 1: Raw Data
You can use data.world as a safe and secure distribution platform for data that you need to move around between teams. If you upload some files to the platform that it doesn’t recognize or that are too big to process, they’ll still be downloadable to anyone you make a contributor on the dataset. There’s a great example of this with ‘.keg’ files in Data4Democracy’s Drug Spending dataset:

Level 2: Previewable Files That Add Context
There are a lot of files that add context to datasets or projects: images of visualizations, documentation in PDF or Markdown form, Python, R, SQL or JavaScript files and notebooks that manipulate data and, my favorite, Vega and Vega-Lite visualization files.
For these files, we’ll do our best to render amazing previews so that people using the datasets and projects can learn from them as quickly as possible. Here’s an example of a dataset on the intelligence of dogs that has visualizations, data, and PDFs (click through to view the PDFs):

And here’s another example of our great Python/Jupyter Notebook previews:

Level 3: Structured Data Files
This is where some real magic happens. When you upload structured data to data.world as Excel files, CSV, JSON, JSON-L, Geo-JSON, sqlite dbs, RDF XML, N-Triples or TTL files (and really, this is an ever expanding list), the data.world ingest engine converts the uploaded data into graph data, making it SQL queryable. This allows data.world to do some really amazing things to help you preview, explore, annotate, and profile your data quickly. This is why we call it ‘data aware’ collaboration.
Here’s some the cool things we do with structured data:
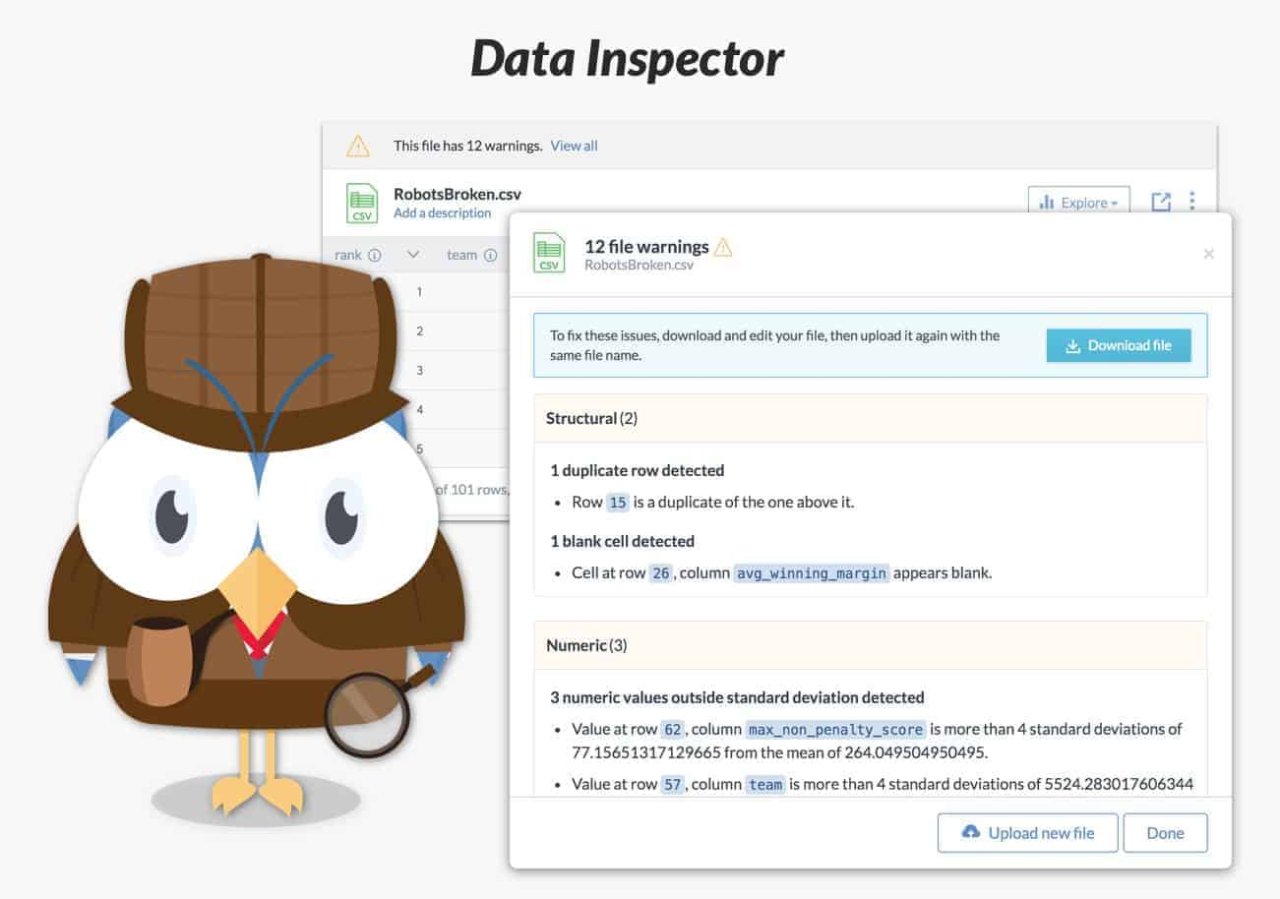
Interactive data previews and profiling — showing you summary statistics, quality assessments, inferenced data types and sample values (and now Data Inspections too!):

Cross-dataset joins with linkable, publishable SQL queries (each query is an API endpoint as well, usable with our Python and R SDKs):

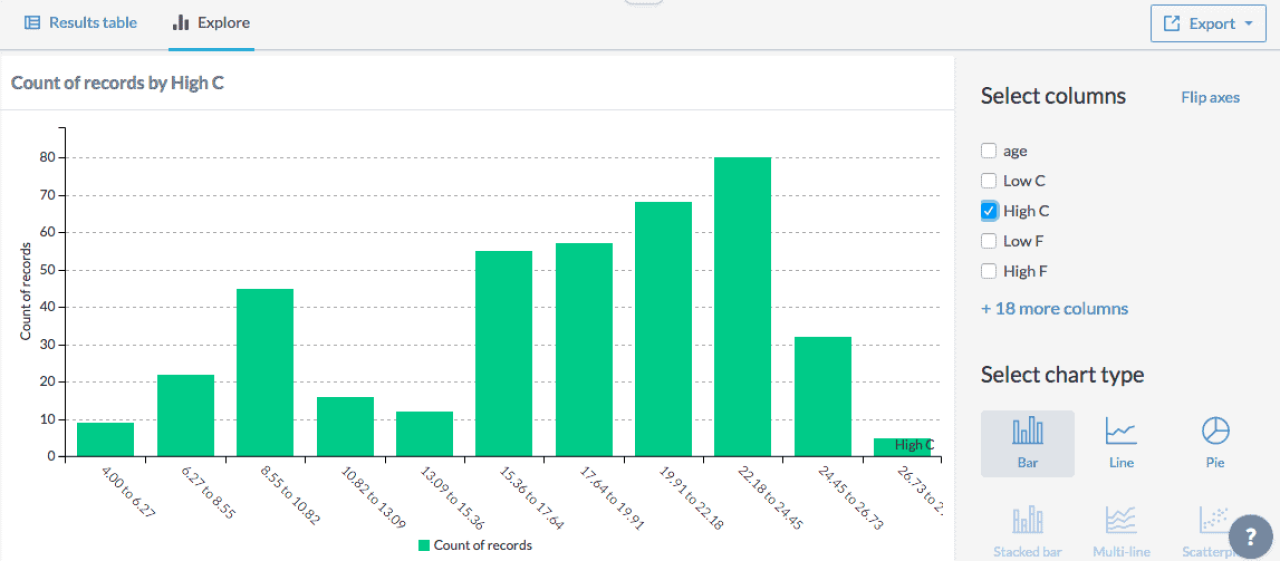
Basic exploratory visualization and shareable charting:

Level 4: Metadata and Social Context
Once your data (raw, context files or structured data) gets into a data.world project or dataset, you can begin to add metadata to your data with our Interactive, collaborative data dictionaries where you can document what your data means:

Also, since it is core to our philosophy here at data.world that data should be social, we keep social context next to the data in the form of Discussions, Activity Streams, and Likes. All of this social context and metadata can be extremely helpful in determining the accuracy, quality, lineage, and provenance of the data that you’re using.
Putting it all together
We think that in order to be successful, a Data Project needs all four types of data and context stored in a durable, trustable way at a known location. If you could only put one kind of file or data into a dataset or project at data.world, you’d still be stuck in a world of silos. Imagine a project that that entails the following:
Some data is sent to you by a vendor or customer (or perhaps a FOIA request) in a PDF (this happens more than you think!) and you need to convert it to machine-readable data. For this example, imagine you’ve found this dataset on USCG rescue stats and you want to extract the data from the PDF it’s embedded in.
You start by creating a data project that describes this task and link the original dataset. Here’s an example data project of how things might look.
Then you might want to use Tabula-py to extract the data table. This could be done with a Jupyter notebook that creates a dataframe and publishes it to your project as raw data.
You see that the raw data needs some clean up, so you load it into Excel and clean up the headers and blank values.
You perform some basic exploratory visualization and publish an insight, or link up with Tableau for a deeper look.
With this sample project you can see how can see how the four types of data and context contribute to successful, self-documenting projects. The flexibility of what you can put into a data.world dataset or Data Project means that you don’t lose that context as you bring in more of your colleagues, friends and coworkers to help you out, adding transparency and reproducibility to what you do!
Want to make your data projects easier/faster/better? Streamline your data teamwork with our Modern Data Project Checklist!