data.world is rapidly establishing itself as the premier site for data scientists and analysts to host and collaborate on datasets. I have been impressed with data.world’s growth and interested in starting to use the platform in my professional projects.
On data.world, datasets can be open and visible to the general public or they can be private, with visibility limited to select contributors. That is sufficient to guarantee the privacy of the data most of the time. However, in some cases, you may be explicitly prohibited from uploading data to the cloud.
Would it be possible to use data.world in a project even when part of the data must not live in the cloud?
It didn’t take me long to answer that question. Fortunately, I also have been doing a meaningful amount of experimentation and development with Apache Drill over the last few years. What impresses me about Drill is its versatility and potential to dramatically increase analytic productivity, open up previously inaccessible data sources, query across data silos, and do so with the common language of ANSI SQL.
As I began experimenting with both, I couldn’t help but wonder if it might be possible to somehow combine the two.
Well, it turns out, it is…
How does it work?
It is possible to query almost any JDBC data source directly using Drill and thanks to the data.world development team, there is a JDBC driver which is compatible with Drill.
What this means is that once you set up Drill with the data.world JDBC driver, you can query and join any dataset that is hosted on data.world with any dataset that Drill can access — remote or local.
A Quick Demo
To try this out, I uploaded a dataset to data.world which is a listing of MAC Addresses and the vendor prefix so that you can identify the manufacturer of a device from its MAC address.
If you aren’t familiar with MAC addresses, they are a hardware identifier which is assigned to network interfaces. The IEEE assigns first six digits of each MAC address which makes it possible to identify the manufacturer from the MAC address.
You can download a list of the vendors and their prefix codes from the IEEE, but it is not in an easy to analyze format, so I wrote a parser to convert this data into a CSV file which I then uploaded to data.world.
Once this is uploaded to data.world, you can execute simple queries against this data such as the one below:
SELECT companyName
FROM dw.cgivre.`mac-address-manufacturers`.`20170426mac_address.csv/20170426mac_address`
WHERE country='CN'
The query above returns the company name from that dataset where the country code is ‘CN’ or China.
However, while this is somewhat interesting, let’s look at another example in which we join local data with the data hosted on data.world.
For this example, I am going to query a PCAP file that is locally hosted, extract the MAC addresses from the file, and join them with the MAC Address data hosted on data.word. The query was as follows:
SELECT SUBSTRING( REGEXP_REPLACE( MACAddressSource, ':', '' ),1,6 ) AS MacAddress,
MACAddressSource,
dw.companyName,
dw.country
FROM dfs.test.`test1.pcap` AS p
JOIN dw.cgivre.`mac-address-manufacturers`.`20170426mac_address.csv/20170426mac_address` AS dw ON dw.prefix = SUBSTRING( REGEXP_REPLACE( MACAddressSource, ':', '' ),1,6 )
The results are shown below:
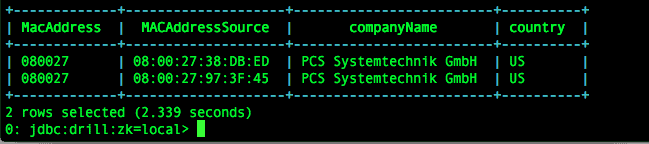
So with absolutely zero data prep, I was able to extract fields from raw data and merge that with data hosted on data.world.
Setting up Drill
In order to query data.world with your Drill instance, you will first need to create a storage plugin for data.world.
To do this, open Drill’s web interface and click on the storage link at the top. Create a new storage plugin by clicking on the link at the bottom. Once you get a blank window, enter the following text:
{
"type": "jdbc",
"driver": "world.data.jdbc.Driver",
"url": "jdbc:data:world:sql:<username>:<dataset>",
"username": "<username>",
"password": "<API Key>",
"enabled": false
}
You will need to get an API Key from data.world which is available here once you have an account. Save this plugin as
dw
.
Querying data.world from Drill
Once you’ve set up the storage plugin, all you really will have to do to query a data.world dataset is modify the
FROM
clause of your query.
The data.world driver is a little different than a regular Drill
FROM
clause in that it has four parts whereas a traditional Drill data source only has three.
dw.<username>.<dataset>.<filename>
Thus to query the example data mentioned in this article, you could use the following
FROM
clause:
dw.cgivre.`mac-address-manufacturers`.`20170426mac_address.csv/20170426mac_address`
As this demonstrates, Apache Drill has once again proven to be a flexible and powerful tool for joining data from disparate datasources. This time, it allowed me to bring the wealth of data on data.world to a context where it can be securely used in conjunction with local and highly sensitive data that otherwise would have been siloed.
About the Author
Mr. Charles Givre recently co-founded a technical training company — GTKCyber — with two former Booz Allen colleagues. GTKCyber has upcoming data science classes in Baltimore and at BlackHat in Las Vegas. He also teaches online classes for O’Reilly about Data Exploration with Apache Drill and Security Data Science and is a co-author for the forthcoming O’Reilly book about Apache Drill.
Mr. Givre has worked as a Senior Lead Data Scientist for Booz Allen Hamilton for six years in the intersection of cyber security and data science. Prior to joining Booz Allen, he worked as a counterterrorism analyst at the Central Intelligence Agency for five years.
Mr. Givre blogs at thedataist.com, shares data on data.world, posts code here, and tweets @cgivre.
Want to make your data projects easier/faster/better? Streamline your data teamwork with our Modern Data Project Checklist!





