At data.world, we strongly believe that the (near) future of data is linked — that in order to maximize data’s potential in enabling humans and computers to solve the world’s biggest problems, we need to connect data according to the principles of Linked Data.
data.world is built on the idea that the best way to connect data is to connect the people who work with data.
By giving data workers a place to collaborate using familiar file formats and their preferred tool chains, we help them add context to their data and capture the knowledge about both the data’s meaning and how it relates to other sources — the essential components of the Semantic Web.
data.world is powered by the open standards for the Semantic Web, RDF and SPARQL.
data.world natively supports datasets in the Resource Description Framework (RDF) format and we build an RDF model for any structured data that comes into the system in a structured format (CSV, JSON, etc). By building this RDF model, the data is instantly queryable via SPARQL, the RDF query language and protocol, and each element is assigned a Uniform Resource Identifier (URI), so any two datasets can be queried jointly or merged for analysis.
Because the majority of data we process is tabular — and vastly more people know SQL than SPARQL — we’ve implemented a SQL-to-SPARQL compiler to execute SQL queries. Compiling to SPARQL allows users to easily join data across multiple datasets, and even bring in data from outside of data.world.
That’s just one of the ways data.world enables powerful Semantic Web features without requiring users to learn new tools or languages. Rest assured, we’ll always adhere to this principle — we want to be the best platform for collaborating on data work using best practices, tools, and techniques that are familiar to the wide variety of people working with data.
But…if you’re into RDF and SPARQL, or curious about Linked Data, this post is for you.
Disclaimer: For the remainder of this post, I’m assuming you know what SPARQL, RDF, and
.ttl
and .nt
files are (or you’re really, really motivated to learn by example). This is definitely an advanced set of features, and not necessary to understand to get value out of data.world!
Here are some ways to leverage data.world’s Semantic Web features today.
Upload Linked Data
When you upload existing RDF datasets to the data catalog, data.world automatically gives you a SPARQL endpoint where you can query your data, and benefit from all the other platform features of data.world — context and summaries, discussion threads, access control and user management, etc.
As an example of how natively linked data works on data.world, check out The Linked Movie Database — this is a collection of movies and people and the connections between them. It was created in 2009, so it’s a little out-of-date, but it’s a great example of what linked data can do.
The dataset contains one
.nt
file — when a file contains RDF Triples, it displays on the dataset page in a file card that shows an overview of the RDF data that lives inside:
 https://data.world/linked-data/linkedmdb
https://data.world/linked-data/linkedmdbThe data is queryable via SPARQL — again, I’m assuming that you know some SPARQL if you’re reading this deep. If you’re interested in learning SPARQL, you can check out this SPARQL Tutorial.
Here’s a sample query that selects the cast of “Pulp Fiction”, and counts the number of movies each actor has appeared in:
 https://data.world/linked-data/linkedmdb/query/eb596383-bdaa-4e9c-8563-5af97a20bf19
https://data.world/linked-data/linkedmdb/query/eb596383-bdaa-4e9c-8563-5af97a20bf19To further highlight the graph nature of this data — you can write a SPARQL query to play “Six Degrees of Kevin Bacon” between any two actors. When you run the linked query, you will get a path of connections to other actors through movies they both acted in that connects John Goodman to Kevin Bacon in 6 steps — try replacing
"John Goodman"
with
"Judy Garland"
or
"Alec Guinness"
or another favorite actor.
Tabular Data as Linked Data
One of the powerful features of our enterprise data catalog is that it provides an RDF view of tabular data as well. So CSV files, Excel Spreadsheets, JSON Lines, and so on are all presented as an RDF model and can be manipulated and merged with the same SPARQL tools.
@markmarkoh
uploaded a dataset with a
table of data about US States. Because it’s a tabular file, we can query the data via SQL:
 https://data.world/markmarkoh/us-state-table/query/52249d67-8f0f-47e1-9908-302dc08abb97
https://data.world/markmarkoh/us-state-table/query/52249d67-8f0f-47e1-9908-302dc08abb97But all the data from that CSV file is also available to query via SPARQL — each row from the original file has been modeled as an entity in an RDF graph:
 https://data.world/markmarkoh/us-state-table/query/5a668a01-f91a-4397-86da-00d3d831ff98
https://data.world/markmarkoh/us-state-table/query/5a668a01-f91a-4397-86da-00d3d831ff98The single value that matches the
?row
variable is a URI representing the row — and if you click on that link, you get a page that looks like this:
 https://markmarkoh.linked.data.world/d/us-state-table/row-state_table-42
https://markmarkoh.linked.data.world/d/us-state-table/row-state_table-42This is an HTML representation of the RDF properties that describe that linked object — you can see that the row has an RDF
type
that is derived from the name of the table it is part of, and a
rowNum
property specifying its position in that table. RDF properties are derived from each column on the table, such as
col-state_table-abbreviation
. You can also retrieve this data in RDF native data formats, by accessing the same URL with an
Accept
header:
$ curl https://markmarkoh.linked.data.world/d/us-state-table/row-state_table-42 -H 'Accept: application/rdf+xml'
<rdf:RDF
xmlns:rdf="https://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="https://purl.org/dc/elements/1.1/"
xmlns:owl="https://www.w3.org/2002/07/owl#"
xmlns:rdfs="https://www.w3.org/2000/01/rdf-schema#"
xmlns:fn="https://www.w3.org/2005/xpath-functions#"
xmlns:foaf="https://xmlns.com/foaf/0.1/"
xmlns:j.0="https://data.world#"
xmlns:xsd="https://www.w3.org/2001/XMLSchema#"
xmlns:j.1="https://markmarkoh.linked.data.world/d/us-state-table/">
...
$ curl https://markmarkoh.linked.data.world/d/us-state-table/row-state_table-42 -H 'Accept: text/turtle'
@prefix owl: <https://www.w3.org/2002/07/owl#> .
@prefix rdf: <https://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix fn: <https://www.w3.org/2005/xpath-functions#> .
@prefix xsd: <https://www.w3.org/2001/XMLSchema#> .
@prefix rdfs: <https://www.w3.org/2000/01/rdf-schema#> .
@prefix foaf: <https://xmlns.com/foaf/0.1/> .
@prefix dc: <https://purl.org/dc/elements/1.1/> .
<https://markmarkoh.linked.data.world/d/us-state-table/row-state_table-42>
a <https://markmarkoh.linked.data.world/d/us-state-table/tbl-state_table> ;
<https://data.world#rowNum> 42 ;
<https://markmarkoh.linked.data.world/d/us-state-table/col-state_table-abbreviation>
"TX" ;
<https://markmarkoh.linked.data.world/d/us-state-table/col-state_table-abbreviation_state_abbreviations-categorical>
...
Going back to the Entity Browser, if you follow the link to
:tbl-state_table
you get a representation of the table that this row lives in:
 https://markmarkoh.linked.data.world/d/us-state-table/tbl-state_table
https://markmarkoh.linked.data.world/d/us-state-table/tbl-state_tableWhere you can see that this entity is an instance of
csvw:Table
,
rdfs:Class
, and
void:Dataset
— with properties indicating the
columnCount
and
rowCount
, and other features of the table.
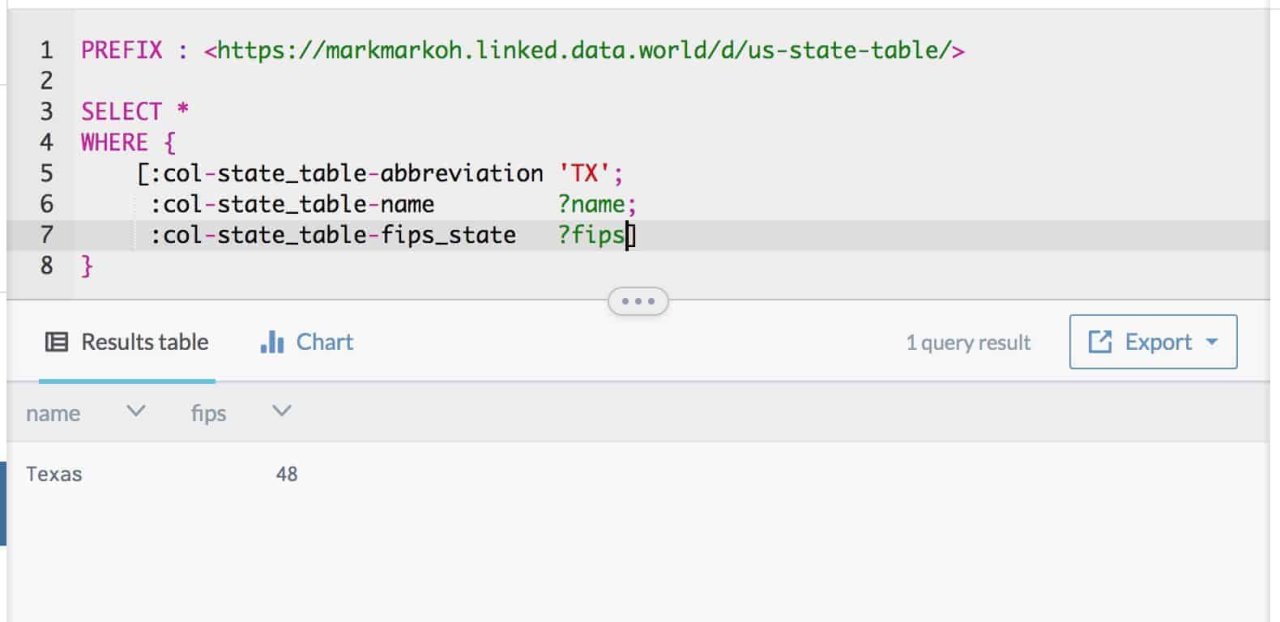
Back in the workspace, I can query the values themselves, rather than the URI for a row entity, much as I would with a SQL query:
 https://data.world/markmarkoh/us-state-table/query/c07cabd6-03ec-48a5-b590-c04b57df1a35
https://data.world/markmarkoh/us-state-table/query/c07cabd6-03ec-48a5-b590-c04b57df1a35Here, I don’t care about getting back the URI for the row itself, I just want to find the row with the
abbreviation
'TX'
and return back the name and FIPS code for the state.
Linking to Linked Data
The point of representing data as links is to be able to refer to concepts via those universal identifiers and make connections between datasets by following those links.
To demonstrate this, let’s look at another simple dataset that contains the adjacency list of US states:
 https://data.world/bryon/state-adjacency
https://data.world/bryon/state-adjacencyThis CSV is represented as a table, so you can query it with SQL:
 https://data.world/bryon/state-adjacency/query/6933a0e1-7caa-496c-a860-ce750fc32f28
https://data.world/bryon/state-adjacency/query/6933a0e1-7caa-496c-a860-ce750fc32f28And, just as any table on data.world, there’s an RDF representation so we can query it with SPARQL:
 https://data.world/bryon/state-adjacency/query/f10755cc-bd9f-48cf-a8ee-45b7acffb23a
https://data.world/bryon/state-adjacency/query/f10755cc-bd9f-48cf-a8ee-45b7acffb23aThis dataset only contains the two-character codes representing each state — it’d be great if we could join in the previous dataset to fill in more details, such as the full name of the state.
In data.world, every dataset you can access is available to you in SPARQL as a named graph — so we can link that dataset in like so:
 https://data.world/bryon/state-adjacency/query/aef2fdad-d04a-409e-a75c-aa13b60e72a7
https://data.world/bryon/state-adjacency/query/aef2fdad-d04a-409e-a75c-aa13b60e72a7Linking to Linked Data ANYWHERE
And it’s not just the data on data.world that’s reachable from your SPARQL queries — any remote SPARQL endpoint is reachable as well by performing a federated query using the
SERVICE
keyword.
For example, we could join in Wikidata, a free RDF knowledge base that exposes a SPARQL endpoint:

Note that the property names in
our query are not very readable — what are
wdt:P883
and
wdt:P2046
? If you follow those links, you’ll get to Wikidata’s Linked Entity Browser for those properties — they stand for the
FIPS 5–2 State Code
and for
area
respectively. Wikidata makes no effort to make the URIs for their entities and properties human-readable, instead the URIs are completely opaque and you can rely on referencing the human-readable
labels in order to understand what’s being described.
Here, we’re fetching the URI for each state in Wikidata (go to https://www.wikidata.org/wiki/Q1612 to see Wikidata’s Linked Entity Browser rendering of its information about Arkansas) and the area of the state in km².
Curating Linked Data
So far we’ve manipulated RDF data natively, manipulated tabular data via an RDF model, and run some queries that used SPARQL to link up data within data.world and between a data.world dataset and external SPARQL endpoints.
We joined state data together using the two-character abbreviation for the states — because we applied the knowledge of what those codes mean to specify that the rows in
@markmarkoh
's
state_table
dataset represent the same entities as the US states from Wikidata. It would be great if we could capture that knowledge about the “sameness” of those two entities
explicitly in the knowledge base, so that information could be used by future human and machine processors of this data.
With a SPARQL
CONSTRUCT
query, we can write a query whose result is another RDF graph (rather than the tabular result set you get from a
SELECT
):
 https://data.world/markmarkoh/us-state-table/query/a8184631-cdfd-4343-81a1-402c5d3d0b13
https://data.world/markmarkoh/us-state-table/query/a8184631-cdfd-4343-81a1-402c5d3d0b13Here, I’ve constructed a new graph which contains a triple for each entity in the source graph linking it to the corresponding Wikidata entity — it’s a linked data crosswalk to connect the concepts in the two graphs.
There are many ways that mapping could be modeled, and many standard taxonomies that could be used to represent that relationship. For the purposes of this example, I’ve just coined a new property name. We could download those results as a
TTL
file, which would look like this:

And since data.world can utilize RDF data natively, I can push that data back into a dataset…
 https://data.world/bryon/rdf-crosswalk-example
https://data.world/bryon/rdf-crosswalk-example…which would allow me to write a query that joins together the
state_table
dataset with Wikidata, using those explicit links between the entities:
 https://data.world/bryon/rdf-crosswalk-example/query/af02380e-247a-4396-9a8a-38da18a8ce0b
https://data.world/bryon/rdf-crosswalk-example/query/af02380e-247a-4396-9a8a-38da18a8ce0bIn this example, I’m pulling the
circuit_court
from the
state_table
dataset, and the
area
property from Wikidata — note that I’m no longer looking up “entities which happen to have the same abbreviation”, I’m following the explicit link
:wikidataEntity
from the crosswalk dataset to the corresponding record in Wikidata.
The Future of Linked Data on data.world
This is a tour of the Linked Data features that data.world offers — if you’re an RDF expert, or you’d like to learn more about how you can leverage this powerful technology, this should be a good jumping-off point to explore Linked Data in data.world.
And if you’re not, then consider this a peek behind the curtain at what’s powering our data catalog software. We’re constantly working on features that bring more of these capabilities forward in more user-friendly ways and integrations with external tools, and we are committed to bringing the power of linked data to bear for everyone who works with data. Stay tuned for what we have in store!
Learn more about the power of Linked Data in this white paper.