Organizations transitioning to cloud-based analytics and data warehousing solutions often discover the complexities of migrating their data and applications to the cloud. Data migration is not just the migration of tabular data but the entire range of applications and jobs that transform and filter that data.
The focus of this article is specifically on the migration of Spark jobs and applications to Snowflake’s Snowpark with focus on the role of a data catalog in facilitating a smooth and successful migration. If you’re not familiar with Snowpark, it’s a Snowflake developer experience allowing developers to write custom code in their preferred language to perform complex data transformations and analytics on top of their data in Snowflake, reducing overhead with an elastic processing engine for scaling purposes.
Data migration is not just the data
Data migration to Snowflake goes beyond transferring tabular data from your on-premise databases to a data warehouse. It involves moving the entire ecosystem of Spark applications, including Spark pipelines using multiple languages that retrieve disparate data for big data processing and analytics.
By migrating to Snowflake, organizations gain enhanced flexibility, improved performance, and a streamlined approach to managing multiple data pipelines and sources. More benefits can be found at Snowflake.
Leveraging a Data Catalog
My colleague, Juan, recently wrote a great article on how to implement a data catalog to optimize and manage the data migration lifecycle. Leveraging a data catalog as part of your cloud migration project provides benefits including:
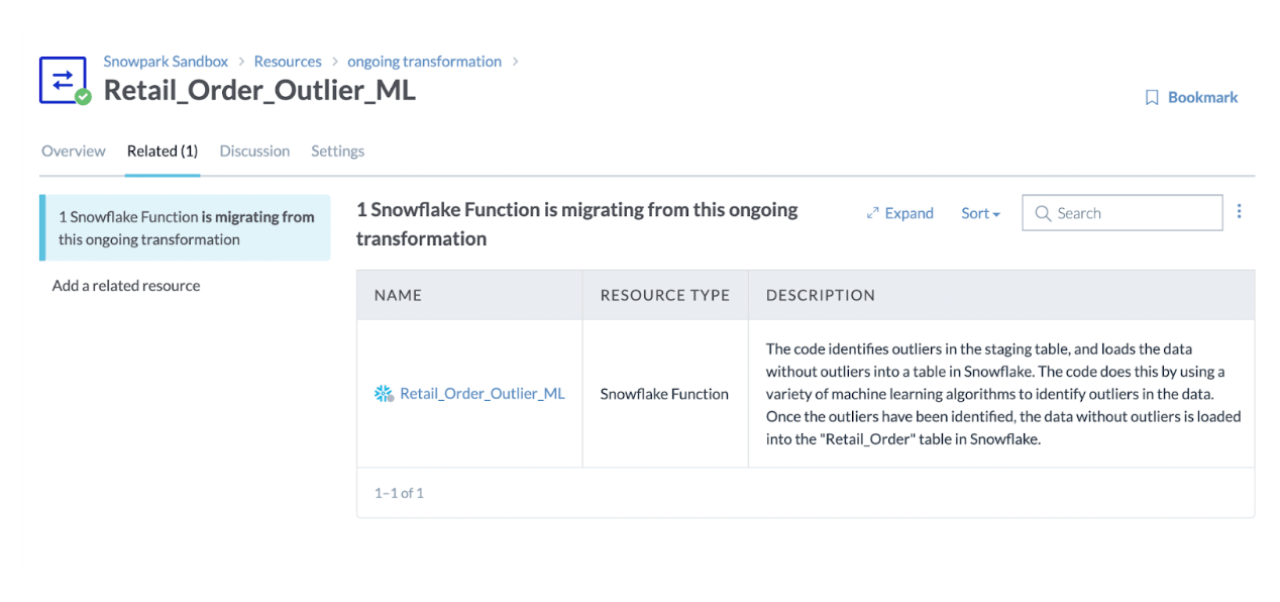
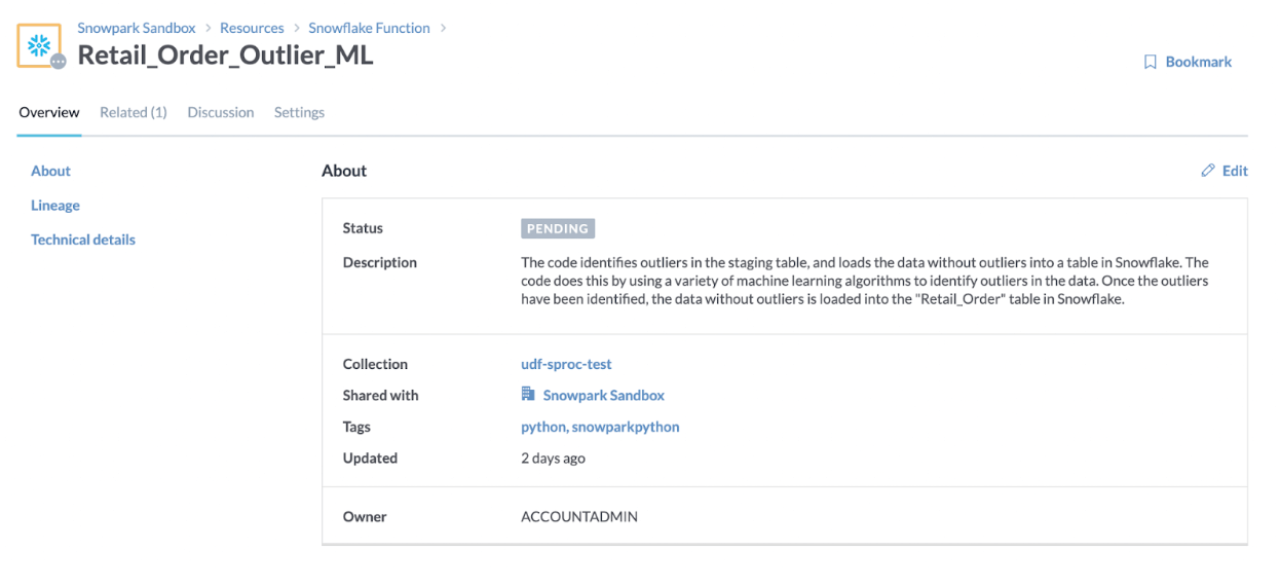
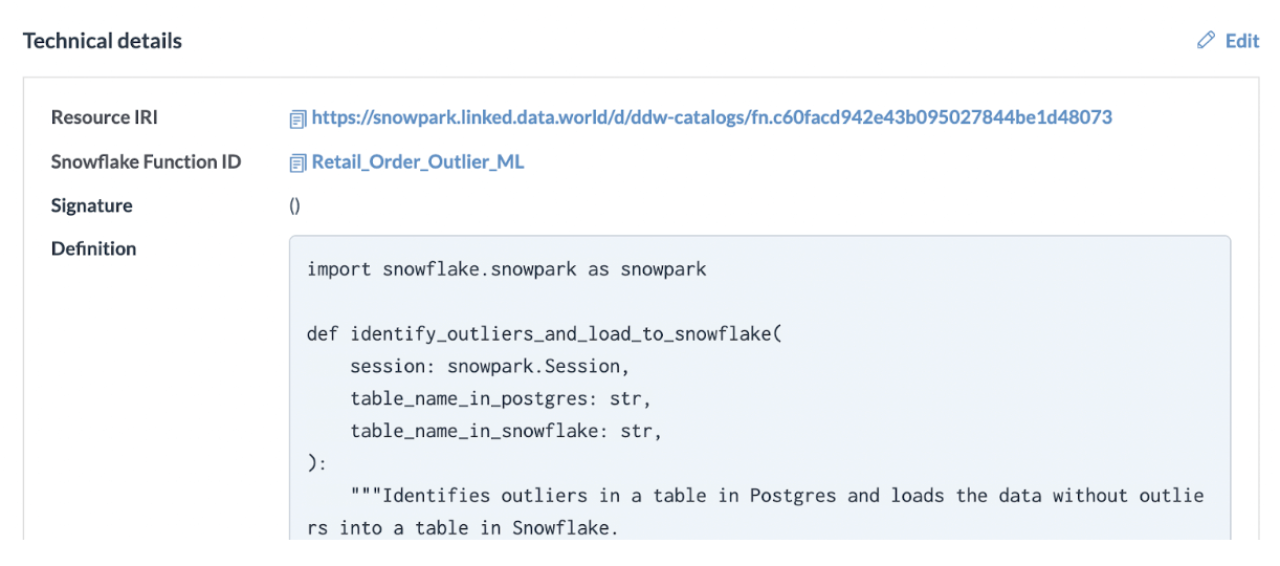
Enhancing Data Team Productivity: A data catalog plays a crucial role in a successful migration by centralizing metadata management. It catalogs the existing metadata used by Spark jobs, such as table schemas, and tracks the migration status (pending completed) of each component. Catalogs also provide impact analysis to identify all resources that may experience downtime and notifications to impacted users. This comprehensive view improves data team productivity, allowing for better planning and coordination during the migration process.
Maximizing Success and Effectiveness: A data catalog facilitates better decision-making by providing insights into the dependencies between Spark jobs and the associated tables. It helps prioritize the migration backlog based on value and complexity, ensuring that high-value applications with lower complexity are migrated first for quick wins.
Building Trust Across Teams: A data catalog promotes collaboration and transparency among different teams involved in the migration process. It serves as a single source of truth, enabling effective communication, documentation, and knowledge sharing. By building trust and facilitating seamless collaboration, the data catalog contributes to the overall success of the migration.
data.world has a tight integration with Snowflake using an agile approach and can accelerate innovations through Data Governance. These tight integrations, powered by a Knowledge Graph, enable users to understand their current data estate in Snowflake and existing Spark resources, and understand object dependencies within Snowflake, providing better reporting and tracking of data migration projects. To learn more, my colleague Lofan also wrote a great article about accelerating innovation through Agile Data Governance.
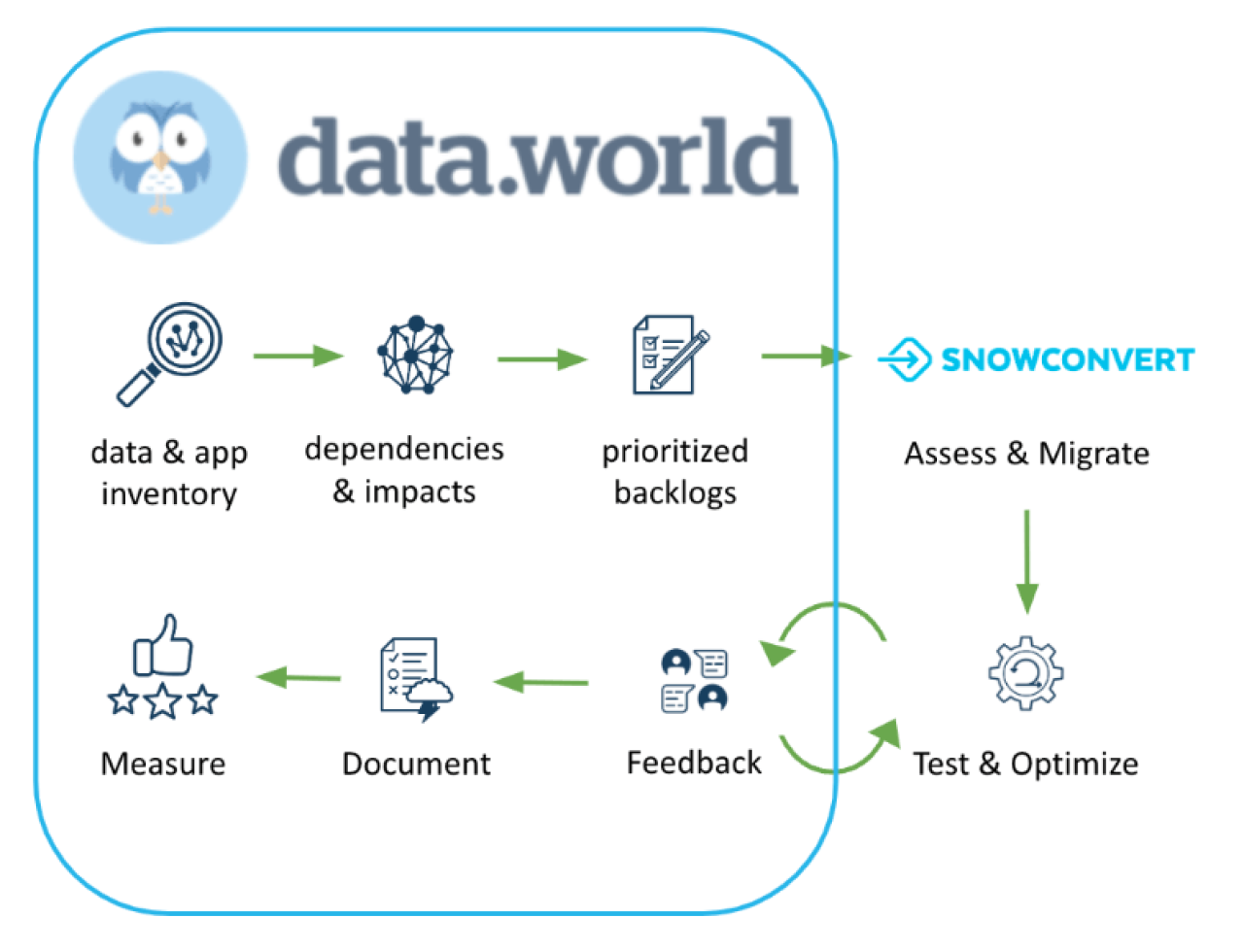
Follow these steps to manage and optimize the migration lifecycle
To ensure a successful migration from Spark to Snowpark, organizations can follow these steps:
Building an Inventory: Identify the scope of applications, including files, jobs/tasks, read/write status, and compute requirements. This inventory helps understand the complexity and scale of the migration effort.
Identifying Dependencies: Determine the dependencies between Spark jobs and the clusters that they run their compute on, and any upstream and downstream tables. This analysis ensures a comprehensive understanding of the migration requirements.
Prioritizing Backlogs: Prioritize the migration backlog based on value and complexity. Focus on high-value, low-complexity applications for quick wins allowing you to achieve success with high ROI to get buy-in for additional migrations, and adopt an agile and lean approach. A catalog based on a Knowledge Graph architecture is the most effective way to determine a data asset value and complexity:
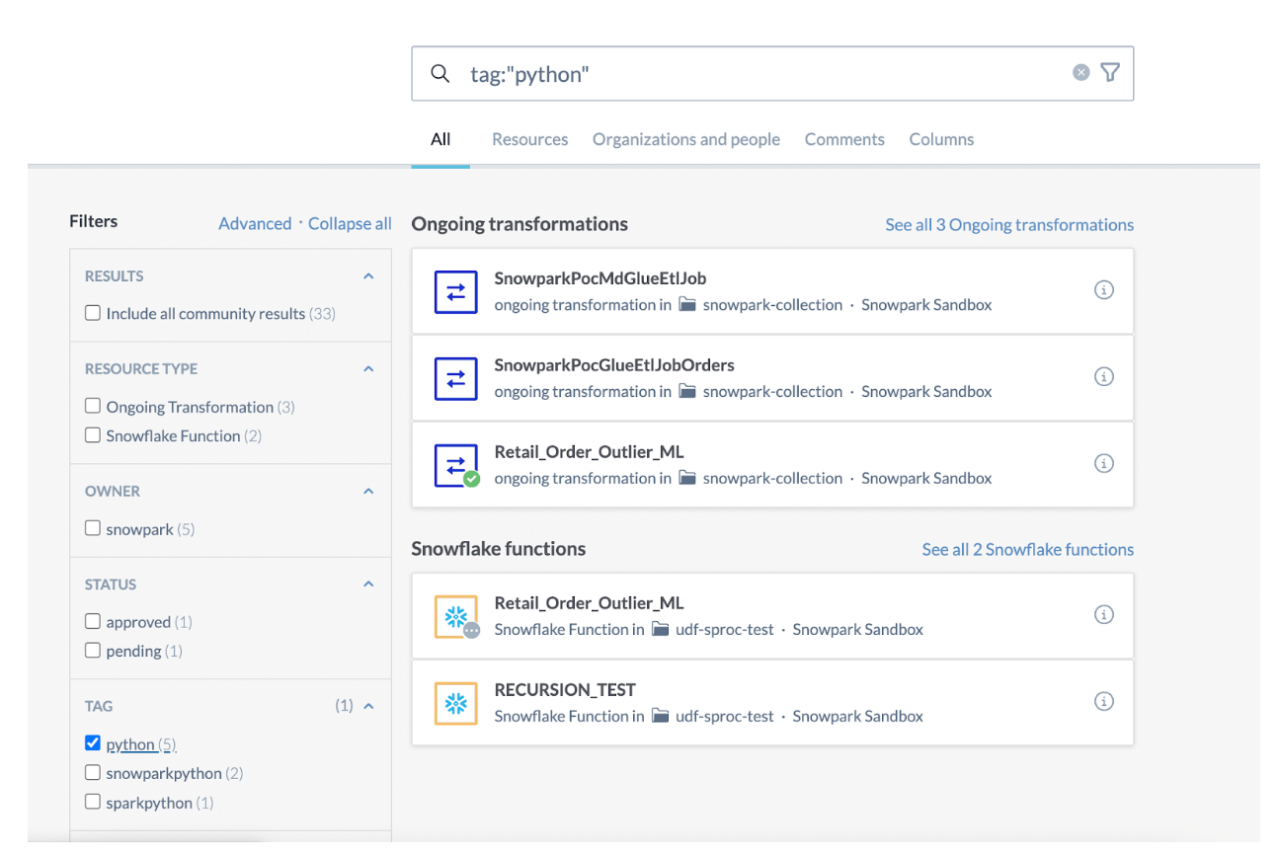
High Value: data.world catalogs all such metrics to identify high-value applications. With knowledge graph architecture, users can quickly identify high-value applications based on query and usage counts from upstream source systems, usage metrics within data.world, popularity tags, job language, and active status of all existing jobs.
Low Complexity: To determine the complexity of data assets, one can utilize a graph dependencies walk within the Knowledge Graph. This involves analyzing the extent of upstream dependencies found in downstream applications. If an application received data from a small set of easily viewed, and understood data sources, it can be considered to have a low level of complexity.
Assessing and Migrating: Assess the existing codebase and migrate it to Snowpark, utilizing SnowConvert to help assess and simplify the process.
Testing and Optimizing: Utilize visual aids during testing to validate the correct functioning of the migrated application and its dependencies. Conduct comprehensive testing to ensure the accuracy of the migration process. Thoroughly test and optimize the migrated applications to validate functionality and benchmark performance against the original Spark jobs.
Gathering User Feedback: Use data.world to seamlessly gather feedback from users to understand their experience with the migrated applications and build trust in the new environment.
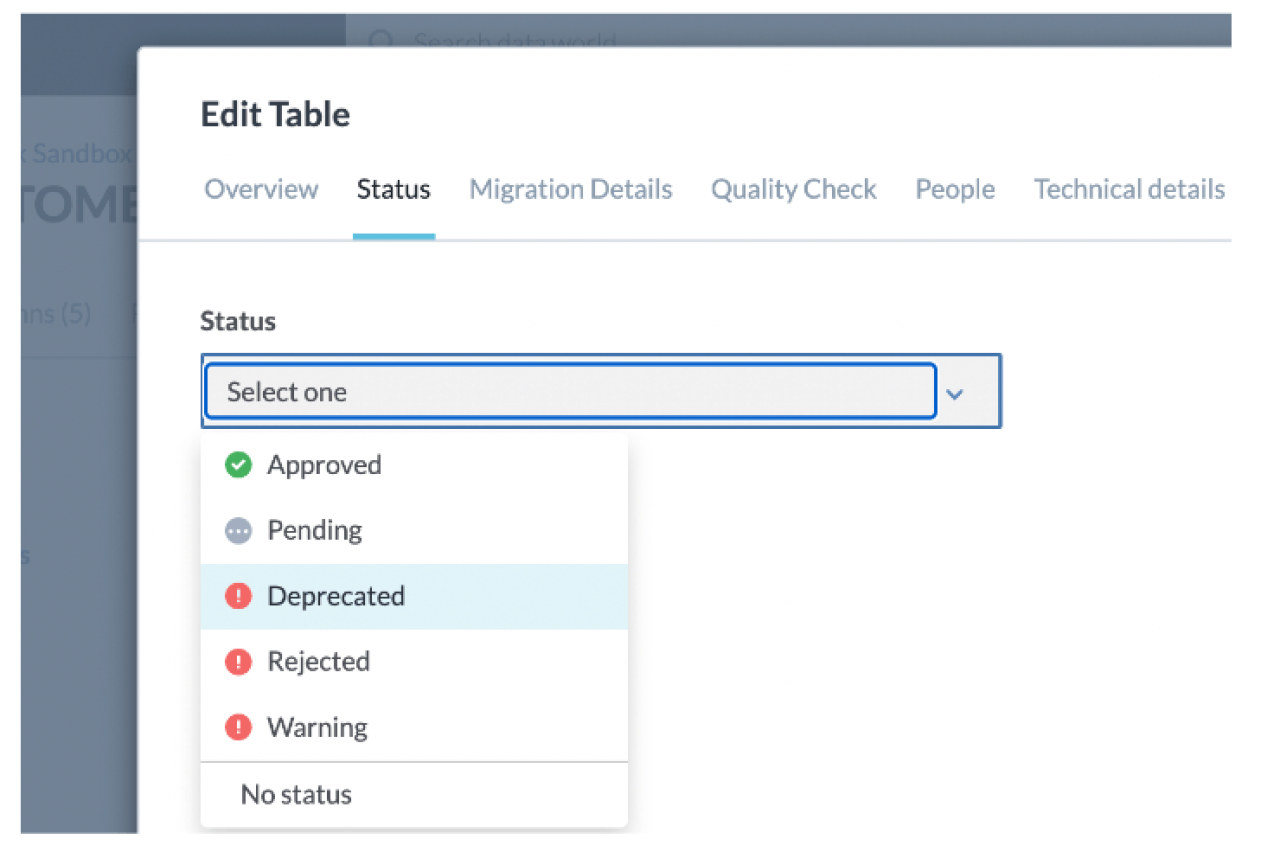
Documenting and Implementing Policies: Document the migrated applications, implement policies to protect sensitive data, and utilize tagging to identify similar objects. Enrich metadata with migration source, description, and migration date, and track the status of the migration process.
Measuring and Iterating: Continuously track and report on the progress of the migration. Learn from the experience and iterate to further enhance the migration process.
Empower your organization
Migrating Spark jobs to Snowpark within the Snowflake ecosystem offers significant benefits in terms of flexibility, performance, collaboration, and security.
Leveraging a data catalog throughout the migration process maximizes productivity, ensures a smooth transition, and builds trust across data teams.
By managing the migration lifecycle and embracing the capabilities of Snowpark and Snowflake, organizations can achieve faster time-to-value, efficient operations, reduced risk, and fewer disruptions in their data processing and analytics workflows.