So you’ve persuaded your data leaders and key stakeholders that the only way to achieve a data-driven culture is by adopting an Agile Data Governance methodology. Great! You’re on your way to becoming an organization where data producers and data consumers work together to the benefit of all.
But where do you start? And what steps do you need to take to shift away from top-down governance and into your new approach?
It all has to do with continual improvement. Read this third post in our Agile Data Governance series to learn how you can get your team rolling on your first-ever agile data sprint so your entire organization can begin to collect, enrich, and iterate on your institutional knowledge.
Preparing for Your First Agile Data Governance Sprint
Top-down governance takes a ‘boil-the-ocean’ approach to implementation and is centered around multiple user groups and/or use cases, often resulting in lengthy implementations and unnecessary work that is not directed by actual end-user feedback.
By contrast, Agile Data Governance adheres to a crawl-walk-run philosophy where efforts are focused around building a prioritized initial use case involving known personas and a small number of data and/or analytics sources. This gets data into the hands of end users fast, so you can immediately begin to measure the impact of your project, and iterate for future use cases.
Process Overview
Agile Data Governance uses a flywheel model with top-down curation from experts and data owners who publish to and enable day-to-day users. Bottom-up consumption and crowdsourcing helps contribute back use cases, metadata suggestions, and analysis insights.
Governance and auditing/measuring is an activity that is an umbrella over the entire program. Overall, the company works together to collect, enrich, and iterate on institutional knowledge.
As you onboard new use cases, new departments or user groups, and new data and analysis source systems, consider how each of these steps can be done successfully, and how the overall cycle can be performed more quickly, effectively, and sustainably.
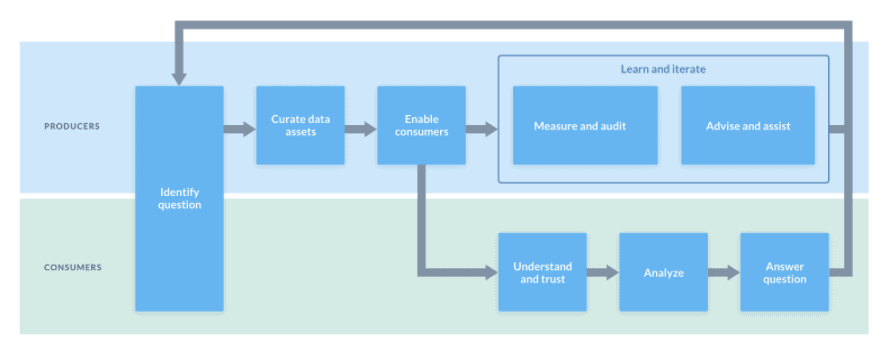
The build-measure-learn loop of Agile Data Governance
Building a Use-case Backlog
A key component of implementing Agile Data Governance is building a use-case backlog. At its core, a use-case backlog is a prioritized list of the common business questions you want your program to solve for.
Here are a few tips to help you get started:
Create epics to capture top-level questions; it’s helpful to express these as scientific hypotheses, i.e. “Increasing user engagement will result in a net revenue retention increase.”
This then drives you create stories like "I need a consistent measure of engagement" and "define net revenue retention"
The stories bucketed under each epic should align to a unit of work; example: curation and data acquisitions, analytics (modeling, dashboards, reports, metrics, etc.)
Align on a peer-review process and definition of done to ensure stories are satisfactorily completed before moving on to new use cases
Iterating
Upon completion of the initial use case, it is important to perform a retrospective and document what you learn. To borrow again from our friends in Open and Agile software development at Product Plan:
A retrospective is a meeting held after a product ships to discuss what happened during the product development and release process, with the goal of improving things in the future based on those learnings and conversations.
For those who have never participated in a retrospective before, Atlassian Team Playbook provides detailed instructions for running one.
Applying this methodology will give you detailed insight into what went right, what went wrong, and what you can do to improve future use-case implementations.
And there you have it; your first agile data governance sprint is complete. Just remember, the key to improving is continued iteration. So do it again, and again, and again.
Want to learn more? Download the Agile Data Governance playbook.
If you'd like to learn more about implementing Agile Data Governance sprints into your data governance workflows, download the Agile Data Governance playbook.





